
00:00:00
Agent 入门实战 原创
✍ 道路千万条,安全第一条。操作不规范,运维两行泪。
最近在学习《AIOps》相关的知识课程,为了让学习有一定的收获,所以将其进行了总结分享,如果你恰好也需要,很荣幸能帮到你。
上个章节我们介绍了《大模型入门实战》,初步了解了如何在不同的场景下接入大模型。本章我们将介绍如何通过大模型来构建智能体 Agent。主要将通过以下几个小节进行介绍:
- 什么是 Agent
- Agent 的四种设计模式
- 从零开发一个 Agent
- Translation Agent 源码和架构分析
- LangGraph Agent 开发实战
- 从零开发个人运维知识库 Agent
另外,文章篇幅较长,请耐心观看。
什么是 Agent
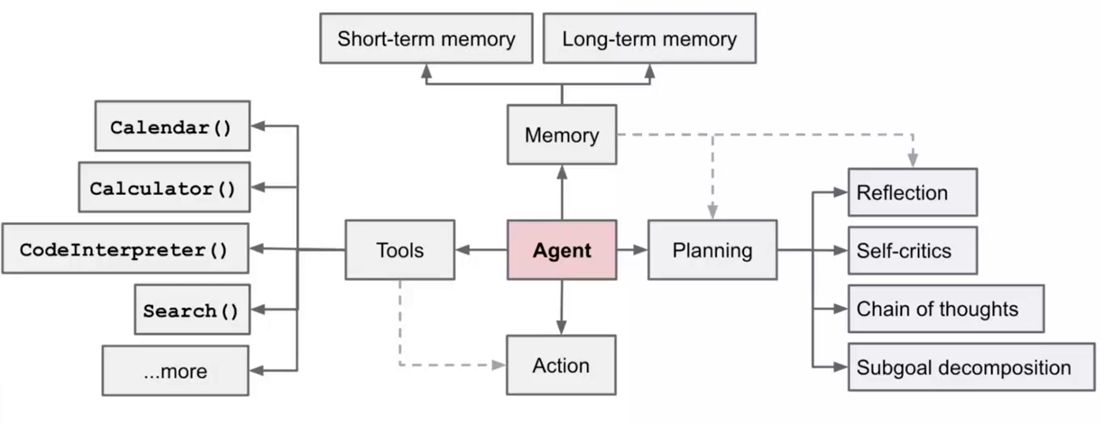
Agent 是一种基于大模型(LLM)构建的智能体,它不仅能理解用户的指令,还能自主思考、规划、调用工具、执行任务并根据反馈调整行为,最终完成复杂的目标。
简单来说,Agent 就是一个会 动脑+动手 的 AI 助手。
一个完整的 Agent 通常具备以下四个核心能力:
- 感知:理解用户输入、环境信息、上下文等
- 思考:进行逻辑推理、任务分解、决策判断
- 行动:调用外部工具执行操作
- 记忆:存储和调用历史信息,支持多轮对话与长期记忆
我们以一个典型的运维场景来举例:
text
用户问:“服务器磁盘快满了,怎么办”
Agent的执行步骤:
1. 思考:需要先查看磁盘的使用情况
2. 行动:调用 get_disk_usage() 函数
3. 获取结果:/var/log 占用80%
4. 思考:可能日志文件过大
5. 行动:调用 analyze_large_files() 函数
6. 获取结果:发现 app.log 文件过大
7. 行动:建议用户清理或者归档日志
8. 输出:建议清理/var/log/app.log 文件,可释放约 5Gb 空间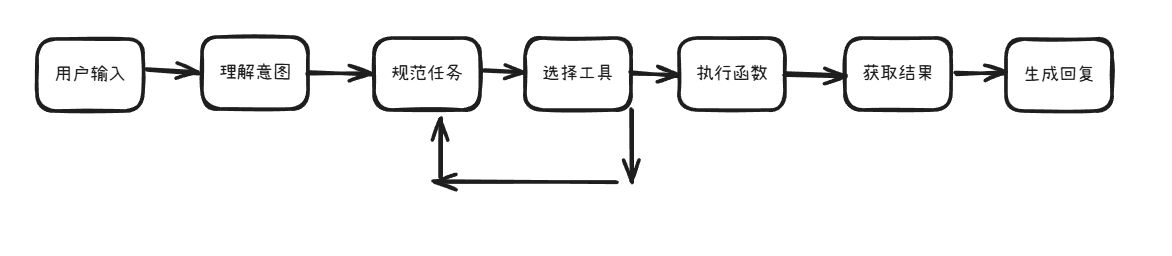
另外,我们也可以将其划分为三大模块:
- 规划模块:负责任务拆解和反思
- 记忆模块:负责存储和检索对话历史、用户偏好以及上下文信息
- 工具模块:负责执行具体操作,是 Agent 的“执行能力”来源
规划模板
规划模块通过任务的拆解和反思,旨在提升大模型的自主决策与自我纠正错误的能力。
- 拆解:通过将复杂任务拆分成多个简单的子任务,通过完成简单子任务来实现复杂任务的整体逻辑。
- 反思:通过 Reat、思维链、思维图和思维数等方法,赋予大模型自动行动与决策能力,提升自我纠错的效率。
记忆模块
记忆模块负责检索历史对话、用户偏好以及上下文信息等来提升交流互动的准确性。
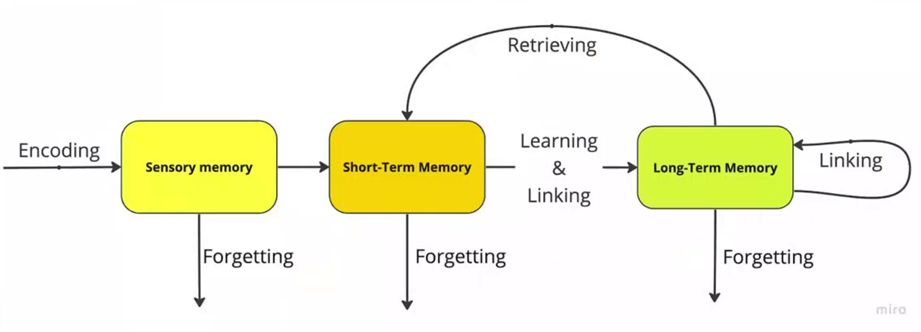
记忆模块分为 短期记忆 和 长期记忆 两种。
- 短期记忆:负责管理当前会话内的上下文,让 AI 能“记住”你刚刚说了什么。
- 长期记忆:负责跨会话地存储和检索信息,让 AI 能“记住”关于你或系统的长期知识。
短期记忆
短期记忆的核心目标是解决单次对话中的上下文连贯性问题。它将当前会话的对话历史(messages)传递给大模型,使其能够理解当前问题的背景。
核心特点:
- 会话内有效:只在当前用户会话中有效,会话结束后通常会被丢弃。
- 依赖 Token 限制:受限于大模型的上下文窗口长度(Context Window)。如果对话过长,必须通过策略进行截断或压缩。
- 实时性高:直接参与模型推理,对当前回复影响最大。
它的局限性在于:
- 无法跨会话使用。
- 会话结束后信息丢失。
- 长对话需要复杂的压缩策略,可能丢失细节。
长期记忆
长期记忆的目标是解决跨会话的知识留存问题。它允许 AI 从过去的交互中学习,并在未来的任何会话中调用这些知识。
核心特点:
- 会话间持久化:信息可以长期存储,即使用户关闭了对话,下次打开时依然可用。
- 可检索性:通常基于向量数据库或图数据库,通过语义搜索(如相似度)来检索相关信息。
- 规模更大:可以存储海量的对话历史、用户偏好、系统知识等。
最后
在实际应用中,两者往往是协调工作的:
- 长期记忆 负责从海量历史数据中检索出与当前问题最相关的片段。
- 这些检索到的片段被注入到 短期记忆 中。
- 短期记忆 将这些历史片段与当前对话历史一起,作为完整的上下文传递给大模型,生成最终回复。
工具模块
工具模块负责执行具体操作,是 Agent 的“执行能力”来源。比如:
- 利用搜索工具,如 Google 搜索,使大模型能够获取和理解最新的现实世界知识,突破知识库日期限制。
- 通过 RAG 搜索私有知识库,增强大模型对个人或特定领域信息的获取能力,补充公共搜索工具的不足。
- 集成代码解释器,运行大模型生成的代码,特别是在数据统计和数学运算场景中,以提高推理准确性与效率。
- 将第三方服务集成至工具模块,通过调用 API,使大模型能够访问和利用内部运维能力,如查询日志、指标,创建工单,甚至部署工作负载。
- 抽象并封装内部运维功能为 API,提供给大模型调用,实现大模型与各种运维服务的无缝整合,提升其功能性和实用性。
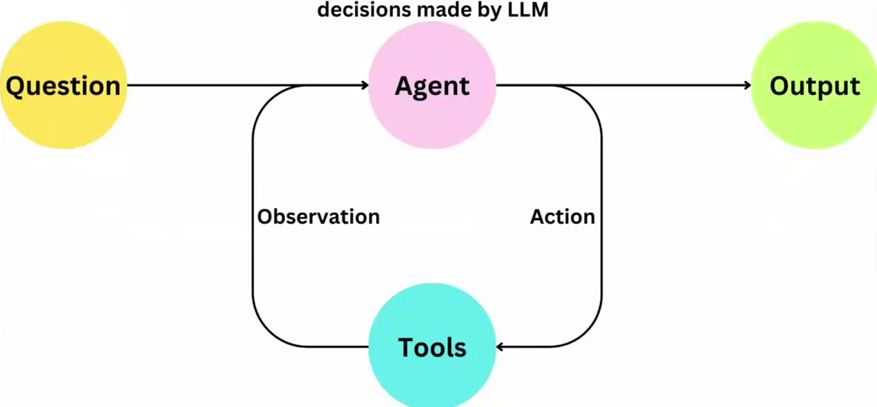
为什么需要 Agent
大模型可以类比为人类的大脑,具有强大的处理和理解能力。人除了有大脑,还有手、脚以及记忆来拥有完成复杂任务,大模型也需要额外的辅助工具来实现全面的交互。Agent 在这里就扮演大模型的手、脚和记忆,为大模型提供执行任务和记忆信息的能力,从此,大模型就获得了与外界进行有效交互的能力,形成了一个完整的系统。
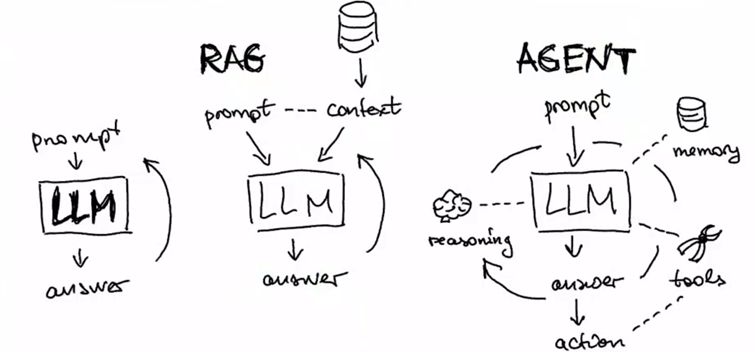
以 RAG 为例,在传统的 RAG 流程中,在进行检索的时候,由于 RAG 流程存在不确定性包括检索出的文档可能与问题不相关,以及大模型在回答问题的时候可能出现幻觉,导致问题未得到有效的解答。这时候如果引入了 RAG Agent,它会从向量数据库中检索文档,然后通过大模型自我判断文档与问题的相关性,若不匹配则自动重写问题并基于近似语义进行新一轮的检索和回答,直到找到匹配的文档。
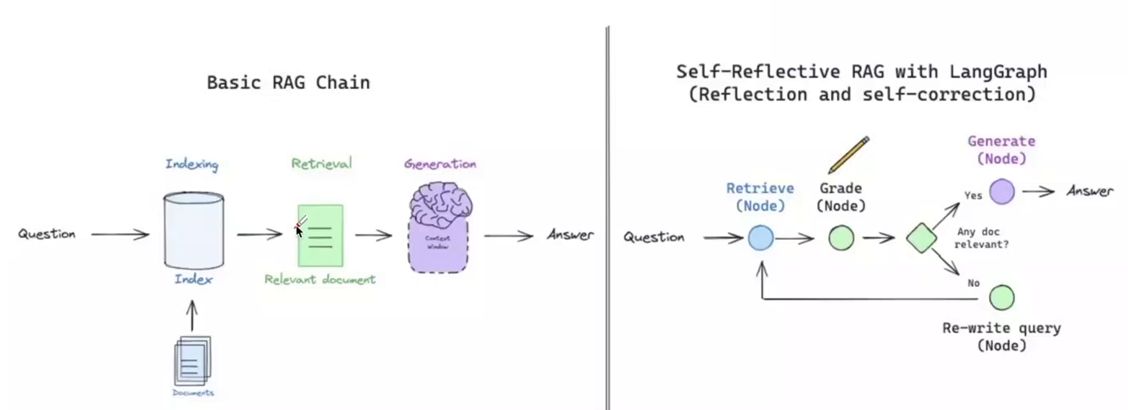
这种循环流程体现了 Agent 的自主思考和自主决策能力,增加了获得更准确答案的可能性,有效克服了传统 RAG 流程的弱点。
Agent 的四种设计模式
在 Agent 开发中,主要有以下四种模式:
- 反馈模式(Reflectio)
- 工具调用模式(Tools)
- 规划模式(Planning)
- 对智能体协作模式
反馈模式
反馈模式是一种让 AI 模型 自我反思 和 自我迭代,不断优化输出,提高任务的准确率。
自我迭代是基于反馈结果进行,确保每次生成的结果都优于前一次,如同人在完成任务时总结并改进工作。以编写代码为例,大模型可基于代码错误信息进行反复优化,直到生成的代码无误且可运行,体现了反馈提高准确性和高质量的优点。
另外,反馈模式的缺点也很明显:
- 多次迭代耗时较长,token 成本较高
- 反馈机制设计较为复杂,通常需要与特定的工具结合,如代码解释器,使设计和实现流程更为复杂
工具调用模式
工具调用模式是通过调用预定义的工具(函数、API、脚本)来与外部世界进行交互,从而获得信息或执行操作。
工具调用模式的优点明显,尤其在数学计算场景,它通过生成的代码可以极大的提高准确性,扩充了模型的能力范围,使其能基于外部系统的数据进行交流。另外,引入工具调用使大模型不再局限于文本交流,可以访问任何外部系统,增强了与人类交互的能力和范围。
当然,工具调用模式也有一些缺点:
- 工具故障会导致模型无法正常回复,增加了系统的不稳定因素
- 复杂任务往往需要多个工具协作完成,增加了系统的整体复杂性,维护成本也不断提高。
规划模式
规划模式是让 AI 模型将复杂任务拆分成多个更小的步骤,通过简化任务来提升准确性。
在这种模式下,它通过将复杂任务拆分成多个小步骤,简化了任务的复杂性。但是其拆分后的步骤依赖性很强,下一步骤的准确性极大依赖于上一个步骤,形成了串行调用模式,上游步骤出现错误会导致下游步骤也产生错误,影响整体任务的准确性。另外,规划通过拆分任务成小步骤,增加了整体任务的耗时和资源消耗。
多智能体协作模式
多智能体协作模式是让多个 Agent 分工协作提高任务的执行效率和准确性。
该模式和规划模式不同的点在于改模式下的智能体可以并行处理任务,每个智能体间的任务依赖性较小,甚至没有依赖,这样极大的提升了任务处理的速度和效率。
不过,多智能体协作模式的主要缺点在于其设计和管理的复杂性较高,需要精心规划智能体之间的交互和协作机制,以确保系统的稳定性和效率。
从零开发一个 Agent
开发目标
我们需要设计一个 RAG Agent 用来回答用户的问题,具体要求如下:
- 输入问题后,通过向量检索寻找相近似文本块,不直接回答问题,而是先由大模型判断文本块是否能解答原始问题。
- 如果文本块不能回答问题,流程会循环返回向量检索步骤,匹配更多文本块,直到找到能回答原始问题的文本块。
- 循环流程设有退出条件,最大循环次数为 15 次,确保过程不会无限进行。
- 每次循环时,向量匹配的文本块数量会递增,即第一次匹配 1 个块,第二次匹配 2 个块,以此类推,增加匹配的范围。
- 核心代码在 python 中通过迭代的方式实现上述循环流程,确保能够逐步扩大搜索范围直至找到合适的答案文本块。
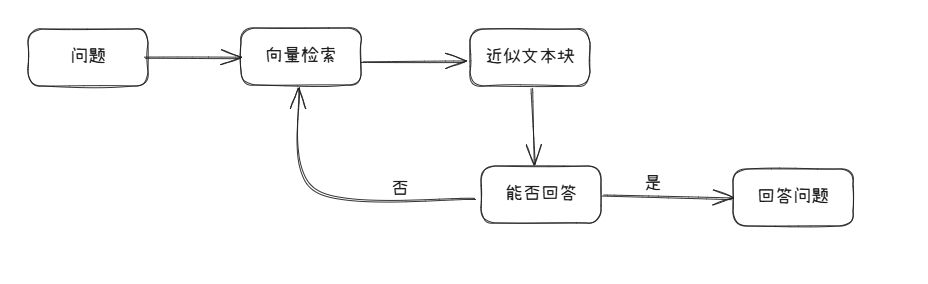
开发实现
1.安装依赖
bash
pip install -qU langchain-openai langchain langchain_community langchainhub
pip install chromadb==0.5.32.引入依赖包
python
from langchain import hub as langchain_hub
from langchain.schema import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.text_splitter import MarkdownHeaderTextSplitter
from langchain_openai import OpenAIEmbeddings
import os
#from langchain_chroma import Chroma
from langchain_community.vectorstores.chroma import Chroma
from langchain_core.prompts import PromptTemplate
from string import Template
import uuid3.将知识库向量化
python
# 声明全局变量
vectorstore = None
def read_knowledge_base() -> list:
# 读取 ./data/data.md 文件作为运维知识库
file_path = os.path.join('data', 'data.md')
with open(file_path, 'r', encoding='utf-8') as file:
docs_string = file.read()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
splits = text_splitter.split_text(docs_string)
print("Length of splits: " + str(len(splits)))
print(splits)
return splits
def save_knowledge_base(splits):
global vectorstore
# 将运维知识库的每一块文本向量化(Embedding)
embeddings = OpenAIEmbeddings(
openai_api_key="sk-u14n5jF9bdZOKWQ47dD365F221144a31B367A637E4Ac4851",
openai_api_base="https://vip.apiyi.com/v1",
model="text-embedding-3-small",
)
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory=os.path.join(os.path.dirname(__file__), "chromadb"),
)
# vectorstore.persist() 方法已过时,从Chroma 0.4.x开始文档会自动持久化4.定义一个方法实现传统 RAG 流程
python
def old_rag():
retriever = vectorstore.as_retriever()
# 提示语模板
template = """使用以下上下文来回答最后的问题。
如果你不知道答案,就说不知道,不要试图编造答案。
最多使用三句话,并尽可能简洁地回答。
在答案的最后一定要说“谢谢询问!”。
{context}
Question: {question}
Helpful Answer:"""
custom_rag_prompt = PromptTemplate.from_template(template)
llm = ChatOpenAI(
model="gpt-4o",
api_key="sk-xxxxx",
base_url="https://vip.apiyi.com/v1",
)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| custom_rag_prompt
| llm
| StrOutputParser()
)
# 传统 RAG 无法回答的问题
res = rag_chain.invoke("谁管的系统最多?")
print("\n\nLLM 回答:", res)
def main():
splits = read_knowledge_base()
save_knowledge_base(splits)
old_rag()
if __name__ == '__main__':
main()其输出如下:
text
匹配到的运维知识库片段:
- **交易量**: 监控每秒交易数,确保系统承载能力。
- **响应时间**: 监控交易的平均响应时间,确保服务性能。
- **系统负载**: 监控CPU、内存等资源使用率,避免资源瓶颈。
- **交易量**: 监控每秒交易数,确保系统承载能力。
- **响应时间**: 监控交易的平均响应时间,确保服务性能。
- **系统负载**: 监控CPU、内存等资源使用率,避免资源瓶颈。
- **访问控制**: 严格控制系统访问权限,实行最小权限原则。
- **数据加密**: 对敏感数据进行加密处理,保护用户隐私。
- **安全审计**: 定期进行安全审计,检查潜在的安全风险。
- **访问控制**: 严格控制系统访问权限,实行最小权限原则。
- **数据加密**: 对敏感数据进行加密处理,保护用户隐私。
- **安全审计**: 定期进行安全审计,检查潜在的安全风险。
LLM 回答: 不知道。谢谢询问!在检索的时候匹配了知识库片段,但是都无法回答我们的问题。
5.使用 Agent RAG 流程
python
# 文本相似性检索
def search_docs(query, k=1):
results = vectorstore.similarity_search_with_score(
query,
k=k,
)
return "\n\n".join(doc.page_content for doc, score in results)
def new_rag():
query = "谁管的系统最多?"
check_can_answer_system_prompt = """
根据上下文识别是否能够回答问题,如果不能,则返回 JSON 字符串 "{"can_answer": false}",如果可以则返回 "{"can_answer": true}"。
上下文:\n $context
问题:$question
"""
llm = ChatOpenAI(model="gpt-4o", api_key="sk-xxxx", base_url="https://vip.apiyi.com/v1")
k = 1
docs = ""
while True:
# 通过检索找到相关文档,每次循环增加一个检索文档数量,最大 15 个文档块
print("第", k, "次检索")
if k > 15:
break
docs = search_docs(query, k)
print("匹配到的文档块: ", docs)
template = Template(check_can_answer_system_prompt)
filled_prompt = template.substitute(question=query, context=docs)
# 检查上下文是否足够回答问题
messages = [
(
"system",
filled_prompt,
),
("human", "开始检查上下文是否足够回答问题。"),
]
llm_message = llm.invoke(messages)
content = llm_message.content
print("\nLLM Res: ", content, "\n")
if content == '{"can_answer": true}':
break
else:
k += 1
print("匹配到能够回答问题的知识库,开始进行回答\n")
# 最终推理
final_system_prompt = """
您是问答任务的助手,使用检索到的上下文来回答用户提出的问题。如果你不知道答案,就说不知道。最多使用三句话并保持答案简洁。
"""
final_messages = [
(
"system",
final_system_prompt,
),
("human", "上下文:\n"+ docs +"\n问题:" + query),
]
llm_message = llm.invoke(final_messages)
content = llm_message.content
print("\nLLM Final Res: ", content, "\n")
def main():
splits = read_knowledge_base()
save_knowledge_base(splits)
# old_rag()
new_rag()
if __name__ == '__main__':
main()其输出如下:
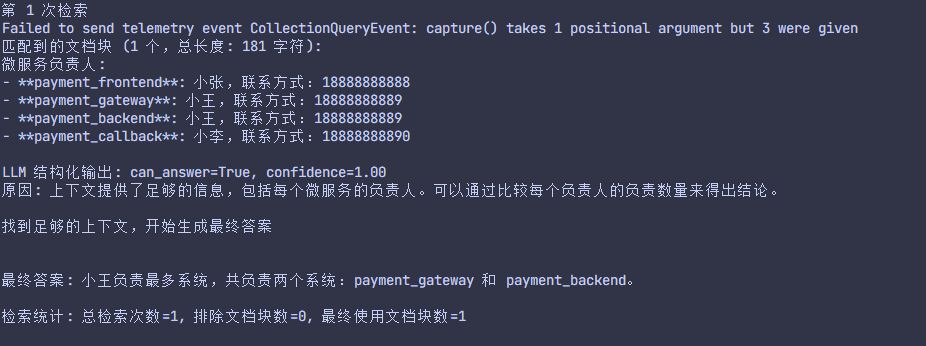
text
匹配到的文档块: 微服务负责人:
- **payment_frontend**: 小张,联系方式:18888888888
- **payment_gateway**: 小王,联系方式:18888888889
- **payment_backend**: 小王,联系方式:18888888889
- **payment_callback**: 小李,联系方式:18888888890
LLM Res: {"can_answer": true}
匹配到能够回答问题的知识库,开始进行回答
LLM Final Res: 小王负责的系统最多,他负责了 **payment_gateway** 和 **payment_backend** 两个系统。6.改进
为了提升检索的准确性,我们可以进行以下改进:
- 在循环增加知识块时,需判断块大小并采用切片策略,避免小模型或上下文超限时出现问题,通过分片让大模型检查是否能回答问题,以解决上下文超限问题。
- 改进向量检索策略,增加 offset 参数过滤已验证无法回答问题的无用文本块,优化在加一过程中持续带入无效信息的问题,提升检索效率和准确性。
- 利用模型获得更稳定的结构化输出,而非仅通过字符串方式判断能否回答问题,这将提高回答的稳定性和结构清晰度。
改进后的代码如下:
python
# 结构化输出模型
class AnswerabilityCheck(BaseModel):
can_answer: bool
confidence: float
reason: str
# 配置参数
MAX_CONTEXT_LENGTH = 4000 # 最大上下文长度
CHUNK_SIZE = 1000 # 单个文档块的最大字符数
MAX_CHUNKS_PER_CHECK = 3 # 每次检查的最大文档块数量
# 改进的文本相似性检索,支持offset过滤
def search_docs(query, k=1, excluded_docs=None):
if excluded_docs is None:
excluded_docs = set()
# 获取更多候选文档以便过滤
search_k = min(k + len(excluded_docs) + 5, 20)
results = vectorstore.similarity_search_with_score(
query,
k=search_k,
)
# 过滤已验证无效的文档块
filtered_results = []
for doc, score in results:
doc_hash = hash(doc.page_content)
if doc_hash not in excluded_docs:
filtered_results.append((doc, score))
if len(filtered_results) >= k:
break
return filtered_results[:k]
# 文档块切片函数
def slice_context(docs, max_length=MAX_CONTEXT_LENGTH):
"""将文档块切片以避免上下文超限"""
sliced_docs = []
current_length = 0
for doc, score in docs:
content = doc.page_content
if current_length + len(content) <= max_length:
sliced_docs.append((doc, score))
current_length += len(content)
else:
# 如果单个文档块过大,进行切片
remaining_length = max_length - current_length
if remaining_length > 100: # 至少保留100字符
sliced_content = content[:remaining_length]
from langchain.schema import Document
sliced_doc = Document(
page_content=sliced_content,
metadata=doc.metadata
)
sliced_docs.append((sliced_doc, score))
break
return sliced_docs
# 格式化文档内容
def format_docs_content(docs_with_scores):
return "\n\n".join(doc.page_content for doc, score in docs_with_scores)
def new_rag(question="谁管的系统最多?"):
original_question = question
# 根据问题类型智能选择检索关键词
def get_search_query(question):
question_lower = question.lower()
if "负责" in question or "管" in question or "系统最多" in question:
return "业务负责人 微服务负责人 系统最多"
elif "响应时间" in question or "性能" in question or "慢" in question:
return "响应时间 性能优化 解决方案"
elif "安全" in question or "攻击" in question:
return "安全问题 安全策略 DDoS"
elif "宕机" in question or "故障" in question:
return "系统宕机 故障排查 应急响应"
else:
# 默认使用问题本身作为检索词
return question
search_query = get_search_query(original_question)
print(f"使用检索关键词: {search_query}")
# 使用结构化输出的LLM
llm = ChatOpenAI(
model="gpt-4o",
api_key="sk-u14n5jF9bdZOKWQ47dD365F221144a31B367A637E4Ac4851",
base_url="https://vip.apiyi.com/v1"
).with_structured_output(AnswerabilityCheck)
# 初始化变量
k = 1
excluded_docs = set() # 存储已验证无效的文档块哈希
final_docs = []
while k <= 15:
print(f"第 {k} 次检索")
# 获取文档块(带过滤)
docs_with_scores = search_docs(search_query, k, excluded_docs)
if not docs_with_scores:
print("没有更多可用的文档块")
break
# 应用切片策略
sliced_docs = slice_context(docs_with_scores, MAX_CONTEXT_LENGTH)
docs_content = format_docs_content(sliced_docs)
print(f"匹配到的文档块 ({len(sliced_docs)} 个,总长度: {len(docs_content)} 字符):")
print(docs_content[:200] + "..." if len(docs_content) > 200 else docs_content)
# 使用结构化输出检查是否能回答问题
check_prompt = f"""
请分析以下上下文是否足够回答用户问题。
上下文:
{docs_content}
问题:{original_question}
请评估:
1. can_answer: 是否能够基于上下文回答问题(true/false)
2. confidence: 回答的置信度(0.0-1.0)
3. reason: 判断的原因
"""
try:
result = llm.invoke(check_prompt)
print(f"\nLLM 结构化输出: can_answer={result.can_answer}, confidence={result.confidence:.2f}")
print(f"原因: {result.reason}\n")
# 如果能够回答且置信度足够高
if result.can_answer and result.confidence >= 0.7:
final_docs = sliced_docs
break
else:
# 将当前无效的文档块加入排除列表
for doc, _ in docs_with_scores:
excluded_docs.add(hash(doc.page_content))
k += 1
except Exception as e:
print(f"结构化输出解析失败: {e}")
# 降级到字符串判断
fallback_llm = ChatOpenAI(
model="gpt-4o",
api_key="sk-u14n5jF9bdZOKWQ47dD365F221144a31B367A637E4Ac4851",
base_url="https://vip.apiyi.com/v1"
)
response = fallback_llm.invoke(f"基于以下上下文,能否回答问题'{original_question}'?请只回答'是'或'否'。\n\n上下文:{docs_content}")
if "是" in response.content:
final_docs = sliced_docs
break
else:
for doc, _ in docs_with_scores:
excluded_docs.add(hash(doc.page_content))
k += 1
if not final_docs:
print("未找到足够的上下文来回答问题")
return
print("找到足够的上下文,开始生成最终答案\n")
# 最终推理
final_llm = ChatOpenAI(
model="gpt-4o",
api_key="sk-u14n5jF9bdZOKWQ47dD365F221144a31B367A637E4Ac4851",
base_url="https://vip.apiyi.com/v1"
)
final_context = format_docs_content(final_docs)
final_prompt = f"""
您是问答任务的助手,使用检索到的上下文来回答用户提出的问题。
如果你不知道答案,就说不知道。最多使用三句话并保持答案简洁。
上下文:
{final_context}
问题:{original_question}
请提供准确、简洁的答案:
"""
final_response = final_llm.invoke(final_prompt)
print(f"\n最终答案: {final_response.content}\n")
# 输出统计信息
print(f"检索统计: 总检索次数={k}, 排除文档块数={len(excluded_docs)}, 最终使用文档块数={len(final_docs)}")
def main():
splits = read_knowledge_base()
save_knowledge_base(splits)
print("=" * 60)
print("测试1: 简单问题 - 谁管的系统最多?")
print("=" * 60)
new_rag("谁管的系统最多?")
print("\n" + "=" * 60)
print("测试2: 复杂问题 - 如何解决支付系统响应时间过长的问题?")
print("=" * 60)
new_rag("如何解决支付系统响应时间过长的问题?")
print("\n" + "=" * 60)
print("测试3: 无法回答的问题 - 今天天气怎么样?")
print("=" * 60)
new_rag("今天天气怎么样?")
if __name__ == '__main__':
main()输出如下:
Translation Agent 源码和架构分析
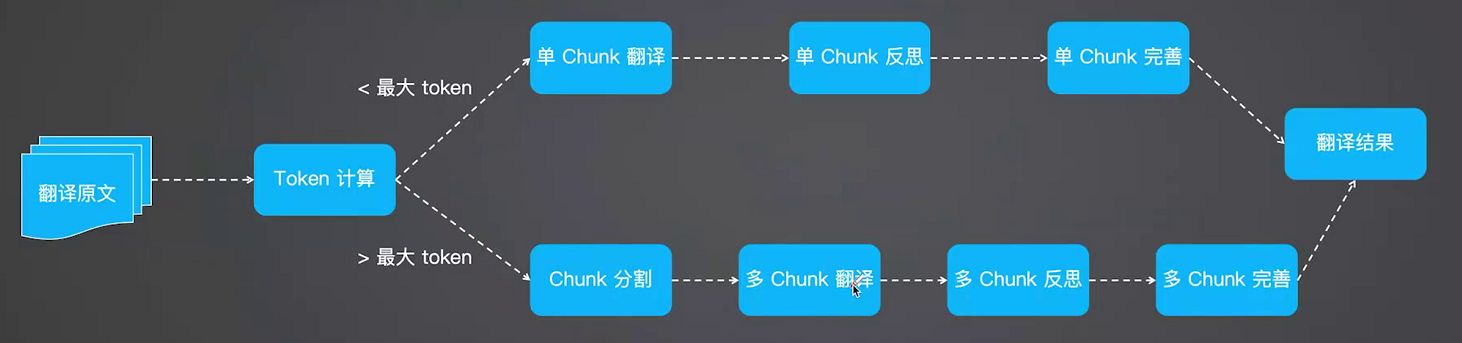
Translation Agent 是吴恩达老师开源的一个 AI 翻译工作流。它是基于反思工作流的智能翻译 Agent,模拟了人类翻译专家的思考过程,分成三个流程:
- 初步翻译:利用 LLM 对文本进行初步翻译,得到初步翻译结果。
- 反思:引导 LLM 对自身翻译结果进行反思,并提出修改意见,例如不准确,不流畅和语言习惯等问题
- 优化输出:根据 LLM 提出的改进意见对翻译结果再次进行优化,得到最终结果。
整体的调用逻辑如下:
python
def one_chunk_translate_text(
source_lang: str, target_lang: str, source_text: str, country: str = ""
) -> str:
translation_1 = one_chunk_initial_translation(
source_lang, target_lang, source_text
)
reflection = one_chunk_reflect_on_translation(
source_lang, target_lang, source_text, translation_1, country
)
translation_2 = one_chunk_improve_translation(
source_lang, target_lang, source_text, translation_1, reflection其中:
one_chunk_initial_translation是初步翻译one_chunk_reflect_on_translation是反思one_chunk_improve_translation是进行优化输出
1.初步翻译
在 one_chunk_initial_translation这个函数中实现将整段文本作为一个块进行初步翻译。
python
# 这个函数生成初步的翻译结果。
def one_chunk_initial_translation(
source_lang: str, target_lang: str, source_text: str
) -> str:
system_message = f"You are an expert linguist, specializing in translation from {source_lang} to {target_lang}."
translation_prompt = f"""This is an {source_lang} to {target_lang} translation, please provide the {target_lang} translation for this text. \
Do not provide any explanations or text apart from the translation.
{source_lang}: {source_text}
{target_lang}:"""
prompt = translation_prompt.format(source_text=source_text)
translation = get_completion(prompt, system_message=system_message)
return translation其中 prompt 部分中文对应如下:
text
您是一位语言专家,擅长从{source_lang}到{target_lang}的翻译。
这是 {source_lang} 到 {target_lang} 的翻译,请提供此文本的 {target_lang} 翻译。
除翻译外,请勿提供任何解释或文本。
{source_lang}:{source_text}
{target_lang}:2.反思
在 one_chunk_reflect_on_translation这个函数中初步翻译结果进行反思和改进建议。
python
# 这个函数获取对初步翻译结果的反馈和改进建议。
def one_chunk_reflect_on_translation(
source_lang: str,
target_lang: str,
source_text: str,
translation_1: str,
country: str = "",
) -> str:
system_message = f"You are an expert linguist specializing in translation from {source_lang} to {target_lang}. \
You will be provided with a source text and its translation and your goal is to improve the translation."
if country != "":
reflection_prompt = f"""Your task is to carefully read a source text and a translation from {source_lang} to {target_lang}, and then give constructive criticism and helpful suggestions to improve the translation. \
The final style and tone of the translation should match the style of {target_lang} colloquially spoken in {country}.
The source text and initial translation, delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT> and <TRANSLATION></TRANSLATION>, are as follows:
<SOURCE_TEXT>
{source_text}
</SOURCE_TEXT>
<TRANSLATION>
{translation_1}
</TRANSLATION>
When writing suggestions, pay attention to whether there are ways to improve the translation's \n\
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),\n\
(ii) fluency (by applying {target_lang} grammar, spelling and punctuation rules, and ensuring there are no unnecessary repetitions),\n\
(iii) style (by ensuring the translations reflect the style of the source text and takes into account any cultural context),\n\
(iv) terminology (by ensuring terminology use is consistent and reflects the source text domain; and by only ensuring you use equivalent idioms {target_lang}).\n\
Write a list of specific, helpful and constructive suggestions for improving the translation.
Each suggestion should address one specific part of the translation.
Output only the suggestions and nothing else."""
else:
reflection_prompt = f"""Your task is to carefully read a source text and a translation from {source_lang} to {target_lang}, and then give constructive criticism and helpful suggestions to improve the translation. \
The source text and initial translation, delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT> and <TRANSLATION></TRANSLATION>, are as follows:
<SOURCE_TEXT>
{source_text}
</SOURCE_TEXT>
<TRANSLATION>
{translation_1}
</TRANSLATION>
When writing suggestions, pay attention to whether there are ways to improve the translation's \n\
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),\n\
(ii) fluency (by applying {target_lang} grammar, spelling and punctuation rules, and ensuring there are no unnecessary repetitions),\n\
(iii) style (by ensuring the translations reflect the style of the source text and takes into account any cultural context),\n\
(iv) terminology (by ensuring terminology use is consistent and reflects the source text domain; and by only ensuring you use equivalent idioms {target_lang}).\n\
Write a list of specific, helpful and constructive suggestions for improving the translation.
Each suggestion should address one specific part of the translation.
Output only the suggestions and nothing else."""
prompt = reflection_prompt.format(
source_lang=source_lang,
target_lang=target_lang,
source_text=source_text,
translation_1=translation_1,
)
reflection = get_completion(prompt, system_message=system_message)
return reflection其中 prompt 部分中文对应如下:
text
您是一位专业语言学家,擅长从 {source_lang} 翻译成 {target_lang}。
您将获得源文本及其翻译,您的目标是改进翻译。
你的任务是仔细阅读原文和从{source_lang}到{target_lang}的翻译,然后提出建设性的批评和有益的建议以改进翻译。
翻译的最终风格和语气应与{country}口语中{target_lang}的风格相匹配。
源文本和初始翻译由 XML 标签 <SOURCE_TEXT></SOURCE_TEXT> 和 <TRANSLATION></TRANSLATION> 分隔,如下所示:
<SOURCE_TEXT>
{source_text}
</SOURCE_TEXT>
<TRANSLATION>
{translation_1}
</TRANSLATION>
在撰写建议时,请注意是否有方法可以改进翻译的
(i) 准确性(通过纠正添加、误译、遗漏或未翻译文本的错误);
(ii) 流畅性(通过应用 {target_lang} 语法、拼写和标点规则,并确保没有不必要的重复);
(iii) 风格(通过确保翻译反映源文本的风格并考虑任何文化背景);
(iv) 术语(通过确保术语使用一致并反映源文本领域;并且仅确保使用等效习语{target_lang});
列出具体、有用的建议以及改进翻译的建设性建议。
每条建议应针对翻译的一个特定部分。
仅输出建议,不输出其他内容。3.优化输出
在 one_chunk_improve_translation这个函数中根据反思改进初步翻译结果。
python
# 这个函数利用反思中的建议来改进初步翻译结果
def one_chunk_improve_translation(
source_lang: str,
target_lang: str,
source_text: str,
translation_1: str,
reflection: str,
) -> str:
system_message = f"You are an expert linguist, specializing in translation editing from {source_lang} to {target_lang}."
prompt = f"""Your task is to carefully read, then edit, a translation from {source_lang} to {target_lang}, taking into
account a list of expert suggestions and constructive criticisms.
The source text, the initial translation, and the expert linguist suggestions are delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT>, <TRANSLATION></TRANSLATION> and <EXPERT_SUGGESTIONS></EXPERT_SUGGESTIONS> \
as follows:
<SOURCE_TEXT>
{source_text}
</SOURCE_TEXT>
<TRANSLATION>
{translation_1}
</TRANSLATION>
<EXPERT_SUGGESTIONS>
{reflection}
</EXPERT_SUGGESTIONS>
Please take into account the expert suggestions when editing the translation. Edit the translation by ensuring:
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),
(ii) fluency (by applying {target_lang} grammar, spelling and punctuation rules and ensuring there are no unnecessary repetitions), \
(iii) style (by ensuring the translations reflect the style of the source text)
(iv) terminology (inappropriate for context, inconsistent use), or
(v) other errors.
Output only the new translation and nothing else."""
translation_2 = get_completion(prompt, system_message)
return translation_2其中 prompt 部分中文对应如下:
text
您是一位语言专家,擅长从{source_lang}到{target_lang}的翻译编辑。
您的任务是仔细阅读,然后编辑从 {source_lang} 到 {target_lang} 的翻译,同时考虑专家建议和建设性批评。
源文本、初始翻译和专家语言学家建议由 XML 标签 <SOURCE_TEXT></SOURCE_TEXT>、 和 <EXPERT_SUGGESTIONS></EXPERT_SUGGESTIONS>
分隔,如下所示:
<SOURCE_TEXT>
{source_text}
</SOURCE_TEXT>
<TRANSLATION>
{translation_1}
</TRANSLATION>
<EXPERT_SUGGESTIONS>
{reflection}
</EXPERT_SUGGESTIONS>
编辑翻译时,请考虑专家建议。编辑译文时,请确保:
(i) 准确性(通过更正添加、误译、遗漏或未翻译文本的错误);
(ii) 流畅性(通过应用 {target_lang} 语法、拼写和标点规则并确保没有不必要的重复);
(iii) 风格(通过确保译文反映源文本的风格);
(iv) 术语(不适合上下文、使用不一致)或
(v) 其他错误;
仅输出新译文,不输出其他内容。4.最后
该 Agent 是基于反思工作来实现,翻译效果优于普通翻译工具,不过其也有以下不足之处:
- 翻译效果依赖 LLM 的能力,不同的 LLM 得到的效果可能不一样
- 相比商业的翻译引擎在特定专业领域略显不足
- 使用有一定门槛,需要安装大量依赖并编写代码
- 基于固定流程,没有 Agent 自我思考的循环机制
接下来将深入探讨该 agent 的开发过程,包括如何可能改进其翻译流程和自我优化机制,以达到更高质量的翻译效果。
LangGraph Agent 开发实战
什么是 LangGraph
LangGraph 是一个构建在 LangChain 之上的库,旨在为 Agent 添加循环运算的能力。
与 LangChain 不同的是,LangGraph 是将 AI 应用的执行流程建模成一个有向图,这个图清晰的定义了应用的状态以及状态之间的流转逻辑。
LangGraph 有以下几个核心概念:
- Stateful Graph:
- Nodes:
- Edges:
Stateful Graph
Stateful Graph 定义有向有环图及其保存的状态,这个状态是整个图的记忆和数据容器,与传统的、无状态的函数调用链不同,LangGraph 图在执行过程中可以读取和修改其内部的状态,从而实现持久化记忆和复杂的控制流。
它的关键优势:
- 持久化 (Persistence):状态可以被保存到数据库(如 SQLite, PostgreSQL, Redis)中,实现会话的中断与恢复、错误回滚和人工干预。
- 多用户支持:通过
configurable.session_id等配置,可以为不同用户维护独立的图状态,完美支持多会话场景。 - 复杂流程:支持条件分支、循环和并行执行,远超线性链式调用的能力。
Nodes
Nodes 是 LangGraph 的节点,每个节点代表一个函数或者一个计算步骤。Node 可以自定义以执行特定的任务,如处理输入、做出决策与外部 API 交互。
节点之间存在相互依赖关系,支持串行或并行执行流程。通过节点,可以实现循环运行的逻辑,这意味着在处理复杂流程或需要重复执行的任务时,具有高度的灵活性和效率。
Edges
边连接图中的节点,定义计算流程。LangGraph 支持条件 Edges,可以根据图的当前状态动态决定要执行的下一个节点。
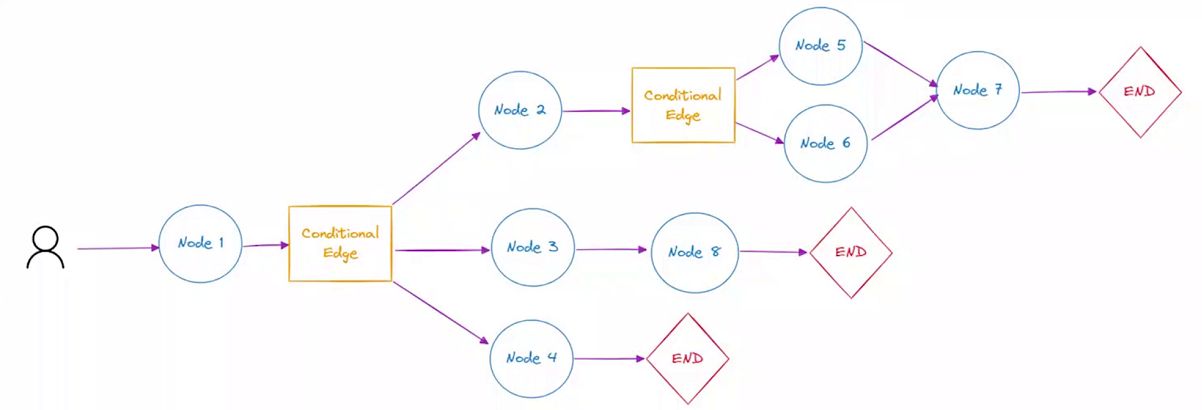
LangGraph 开发实战
1.LangGraph 单节点示例
这里将使用 langGraph 来实现一个简单的聊天功能。
(1)先安装依赖
bash
pip install langgraph langsmith langchain-openai(2)开发代码
python
# LangGraph 简单聊天机器人示例
# 演示如何使用 LangGraph 创建一个基本的对话工作流
# 导入必要的类型定义
from typing import TypedDict, Annotated
# 导入 OpenAI 聊天模型
from langchain_openai import ChatOpenAI
# 导入消息处理和图形构建相关模块
from langgraph.graph.message import add_messages
from langgraph.graph import StateGraph
# 导入用于处理字节流的模块
from io import BytesIO
# 尝试导入 matplotlib 用于图形显示,如果失败则标记为不可用
try:
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
MATPLOTLIB_AVAILABLE = True
except ImportError:
MATPLOTLIB_AVAILABLE = False
# 初始化 OpenAI 聊天模型
# 使用 GPT-4o 模型,配置 API 密钥和基础 URL
llm = ChatOpenAI(
model="gpt-4o",
api_key="sk-xxxx",
base_url="https://vip.apiyi.com/v1"
)
# 定义状态类,用于在工作流中传递数据
# messages: 存储对话历史的消息列表,使用 add_messages 函数进行累积
class State(TypedDict):
messages: Annotated[list, add_messages]
# 定义聊天节点函数
# 接收当前状态,调用 LLM 生成回复,并返回新的消息状态
def chat(state: State):
# 使用 LLM 处理当前的消息历史
response = llm.invoke(state["messages"])
# 返回包含 LLM 回复的新状态
return {"messages": [response]}
# 构建工作流图(单节点简单结构)
# 创建状态图实例
workflow = StateGraph(State)
# 添加聊天节点
workflow.add_node(chat)
# 设置入口点为聊天节点
workflow.set_entry_point("chat")
# 设置结束点为聊天节点
workflow.set_finish_point("chat")
# 编译工作流图
graph = workflow.compile()
# 生成并显示工作流图形
try:
# 获取工作流图的 PNG 格式数据
png_data = graph.get_graph().draw_mermaid_png()
# 将图形数据保存为 PNG 文件
with open("workflow_graph.png", "wb") as f:
f.write(png_data)
print("✅ 工作流图形已保存为 workflow_graph.png")
# 如果 matplotlib 可用,尝试在窗口中显示图形
if MATPLOTLIB_AVAILABLE:
try:
# 从字节流中读取图像数据
img = mpimg.imread(BytesIO(png_data))
# 创建图形窗口
plt.figure(figsize=(10, 6))
# 显示图像
plt.imshow(img)
# 隐藏坐标轴
plt.axis('off')
# 设置标题
plt.title('LangGraph Workflow')
# 显示图形
plt.show()
print("✅ 图形已在新窗口中显示")
except Exception as display_error:
print(f"⚠️ 无法在窗口显示图形: {display_error}")
print("💡 提示: 请直接打开 workflow_graph.png 文件查看工作流图")
else:
print("⚠️ matplotlib未安装,无法显示图形")
print("💡 提示: 请直接打开 workflow_graph.png 文件查看工作流图")
print("💡 或运行: pip install matplotlib 来安装图形显示支持")
except Exception as e:
print(f"❌ 无法生成图形: {e}")
print("💡 提示: 请确保已安装 graphviz 和相关依赖")
# 主聊天循环
while True:
# 获取用户输入
user_input = input("用户: ")
# 检查是否退出
if user_input.lower() == "exit":
break
# 通过工作流图处理用户消息
# graph.stream() 返回处理过程中的事件流
for event in graph.stream({"messages": ("user", user_input)}):
# 遍历事件中的值
for value in event.values():
# 打印 AI 助手的最新回复
print("Assistant:", value["messages"][-1].content)画出的图如下:
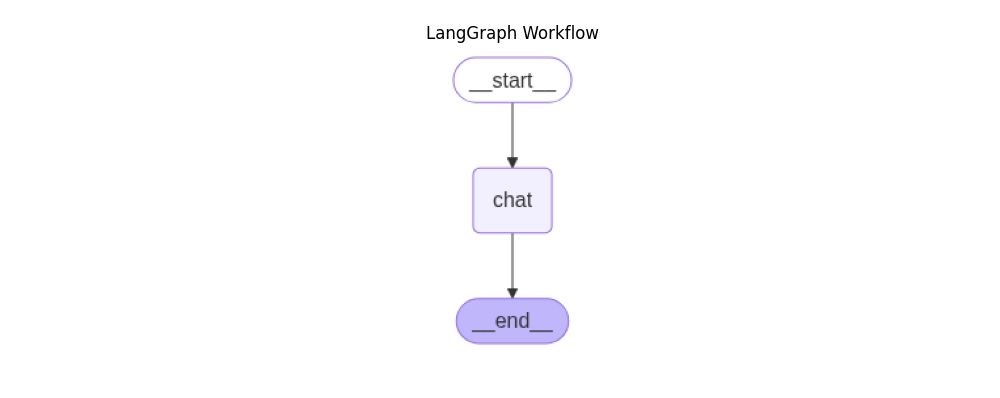
我们只添加了一个 chat 节点,然后设置开始和结束都是 chat 以形成闭环。
2.用 LangGraph 实现 Translation Agent
我们在对吴恩达老师的 Translation Agent 进行源码分析的时候说过,该 Agent 的核心步骤就三个:
- 初步翻译
- 反思
- 优化输出
那我们使用 LangGraph 进行改造的时候也要遵循这三个核心步骤。
(1)安装依赖包
bash
pip install langgraph langsmith langchain-openai(2)引入依赖包
python
from typing import TypedDict, Annotated
from langchain_openai import ChatOpenAI
from langgraph.graph.message import add_messages
from langgraph.graph import StateGraph
from io import BytesIO
try:
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
MATPLOTLIB_AVAILABLE = True
except ImportError:
MATPLOTLIB_AVAILABLE = False
from langgraph.graph import StateGraph, START, END(2)定义状态类,用于在工作流中传递数据
python
# 初始化 OpenAI 聊天模型
# 使用 GPT-4o 模型,配置 API 密钥和基础 URL
llm = ChatOpenAI(
model="gpt-4o",
api_key="sk-xxxx",
base_url="https://vip.apiyi.com/v1"
)
# 定义状态类,用于在工作流中传递数据
# messages: 存储对话历史的消息列表,使用 add_messages 函数进行累积
class State(TypedDict):
messages: Annotated[list, add_messages](3)、定义初步翻译的方法
python
def initial_translation(state: State):
source_text = state["messages"][-1].content
system_prompt = f"You are an expert linguist, specializing in translation from {source_lang} to {target_lang}."
translation_prompt = f"""This is an {source_lang} to {target_lang} translation, please provide the {target_lang} translation for this text. \
Do not provide any explanations or text apart from the translation.
{source_lang}: {source_text}
{target_lang}:"""
messages = [
(
"system",
system_prompt,
),
("human", translation_prompt),
]
return {"messages": [llm.invoke(messages)]}(4)、定义反思的方法
python
def reflect_on_translation(state: State):
country = "America"
# 获取输入的原文(User 消息)
source_text = state["messages"][-2].content
# 获取翻译(Assistant 消息)
translation_1 = state["messages"][-1].content
system_message = f"You are an expert linguist specializing in translation from {source_lang} to {target_lang}. \
You will be provided with a source text and its translation and your goal is to improve the translation."
reflection_prompt = f"""Your task is to carefully read a source text and a translation from {source_lang} to {target_lang}, and then give constructive criticism and helpful suggestions to improve the translation. \
The final style and tone of the translation should match the style of {target_lang} colloquially spoken in {country}.
The source text and initial translation, delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT> and <TRANSLATION></TRANSLATION>, are as follows:
<SOURCE_TEXT>
{source_text}
</SOURCE_TEXT>
<TRANSLATION>
{translation_1}
</TRANSLATION>
When writing suggestions, pay attention to whether there are ways to improve the translation's \n\
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),\n\
(ii) fluency (by applying {target_lang} grammar, spelling and punctuation rules, and ensuring there are no unnecessary repetitions),\n\
(iii) style (by ensuring the translations reflect the style of the source text and take into account any cultural context),\n\
(iv) terminology (by ensuring terminology use is consistent and reflects the source text domain; and by only ensuring you use equivalent idioms {target_lang}).\n\
Write a list of specific, helpful and constructive suggestions for improving the translation.
Each suggestion should address one specific part of the translation.
Output only the suggestions and nothing else."""
messages = [
(
"system",
system_message,
),
("human", reflection_prompt),
]
return {"messages": [llm.invoke(messages)]}(5)定义优化输出的方法
python
def improve_translation(state: State):
# 输入原文(User 消息)
source_text = state["messages"][-3].content
# 初始翻译结果(Assistant 消息)
translation_1 = state["messages"][-2].content
# 反思建议(Assistant 消息)
reflection = state["messages"][-1].content
system_message = f"You are an expert linguist, specializing in translation editing from {source_lang} to {target_lang}."
improve_prompt = f"""Your task is to carefully read, then edit, a translation from {source_lang} to {target_lang}, taking into
account a list of expert suggestions and constructive criticisms.
The source text, the initial translation, and the expert linguist suggestions are delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT>, <TRANSLATION></TRANSLATION> and <EXPERT_SUGGESTIONS></EXPERT_SUGGESTIONS> \
as follows:
<SOURCE_TEXT>
{source_text}
</SOURCE_TEXT>
<TRANSLATION>
{translation_1}
</TRANSLATION>
<EXPERT_SUGGESTIONS>
{reflection}
</EXPERT_SUGGESTIONS>
Please take into account the expert suggestions when editing the translation. Edit the translation by ensuring:
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),
(ii) fluency (by applying {target_lang} grammar, spelling and punctuation rules and ensuring there are no unnecessary repetitions), \
(iii) style (by ensuring the translations reflect the style of the source text)
(iv) terminology (inappropriate for context, inconsistent use), or
(v) other errors.
Output only the new translation and nothing else."""
messages = [
(
"system",
system_message,
),
("human", improve_prompt),
]
return {"messages": [llm.invoke(messages)]}(6)创建 StateGraph
python
workflow = StateGraph(State)
# 添加节点
workflow.add_node("initial_translation", initial_translation)
workflow.add_node("reflect_on_translation", reflect_on_translation)
workflow.add_node("improve_translation", improve_translation)
# 定义 DAG
workflow.set_entry_point("initial_translation")
workflow.add_edge("initial_translation", "reflect_on_translation")
workflow.add_edge("reflect_on_translation", "improve_translation")
workflow.add_edge("improve_translation", END)
#workflow.add_edge("chat", "__end__")
#workflow.set_finish_point("chat")
graph = workflow.compile()
# 生成并显示翻译工作流图形
try:
# 获取工作流图的 PNG 格式数据
png_data = graph.get_graph().draw_mermaid_png()
# 将图形数据保存为 PNG 文件
with open("translation_workflow_graph.png", "wb") as f:
f.write(png_data)
print("✅ 翻译工作流图形已保存为 translation_workflow_graph.png")
# 如果 matplotlib 可用,尝试在窗口中显示图形
if MATPLOTLIB_AVAILABLE:
try:
# 从字节流中读取图像数据
img = mpimg.imread(BytesIO(png_data))
# 创建图形窗口
plt.figure(figsize=(12, 8))
# 显示图像
plt.imshow(img)
# 隐藏坐标轴
plt.axis('off')
# 设置标题
plt.title('Translation Agent Workflow')
# 显示图形
plt.show()
print("✅ 翻译工作流图形已在新窗口中显示")
except Exception as display_error:
print(f"⚠️ 无法在窗口显示图形: {display_error}")
print("💡 提示: 请直接打开 translation_workflow_graph.png 文件查看工作流图")
else:
print("⚠️ matplotlib未安装,无法显示图形")
print("💡 提示: 请直接打开 translation_workflow_graph.png 文件查看工作流图")
print("💡 或运行: pip install matplotlib 来安装图形显示支持")
except Exception as e:
print(f"❌ 无法生成翻译工作流图形: {e}")
print("💡 提示: 请确保已安装 graphviz 和相关依赖")(7)测试翻译效果
python
# 主程序:处理用户输入的翻译请求
print("\n=== LangGraph 翻译代理 ===")
print("支持中文到英文的高质量翻译")
print("工作流程:初始翻译 -> 反思评估 -> 改进翻译\n")
user_input = input("请输入要翻译的中文内容: ")
print("\n开始翻译处理...\n")
# 通过工作流处理翻译请求
events = graph.stream(
{"messages": [("user", user_input)]}, stream_mode="values"
)
# 显示每个步骤的处理结果
step_names = ["初始翻译", "反思评估", "最终翻译"]
step_count = 0
for event in events:
if step_count < len(step_names):
print(f"=== {step_names[step_count]} ===")
step_count += 1
event["messages"][-1].pretty_print()
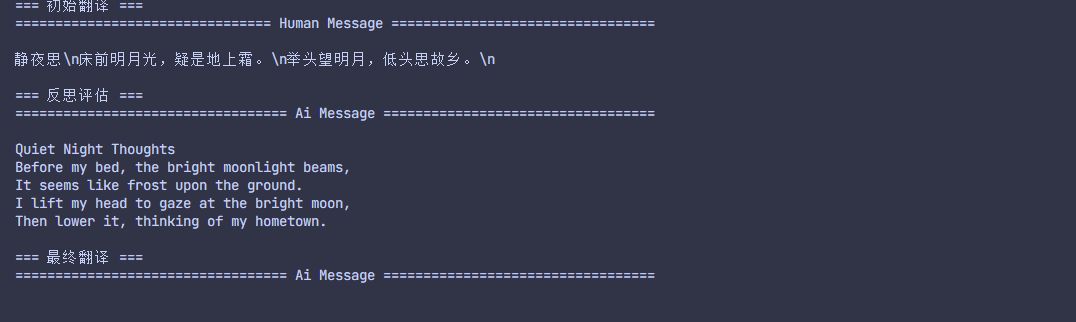
print()输出的状态图如下:
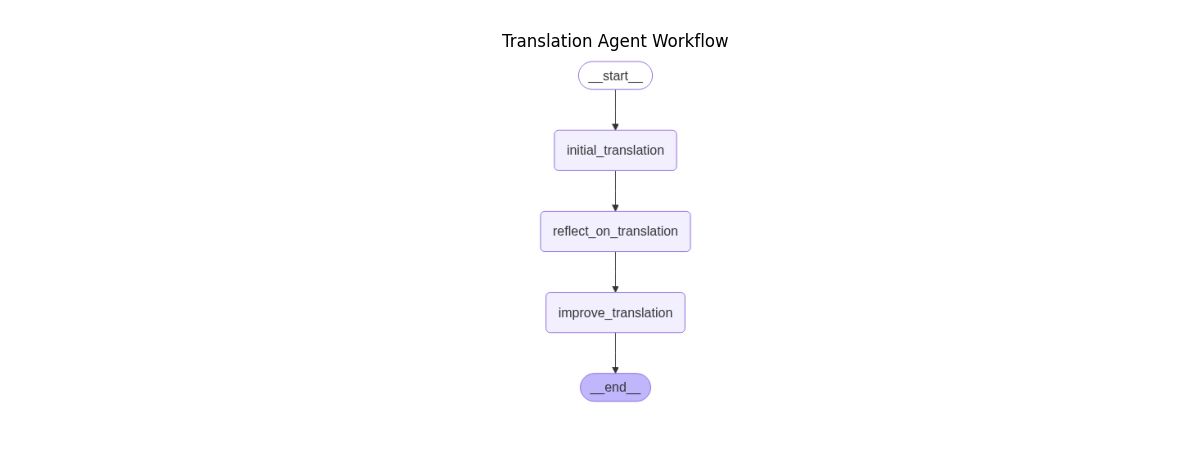
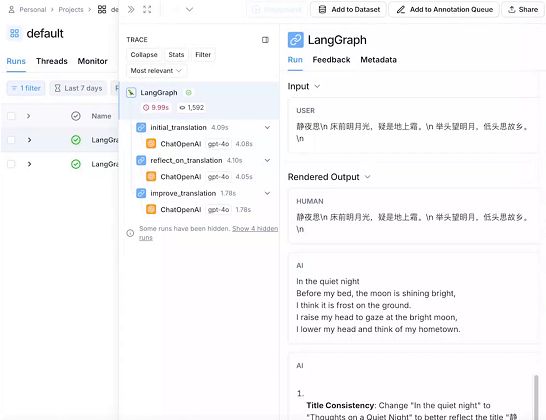
翻译过程如下:
(8)接入 LangSmith
LangSmith 是 Agent 开发的调试、日志和追踪平台,与 LangChain、LangGraph 原生集成。
它的核心功能主要有:
- 调试和追踪:当你的 LangChain 应用运行时,LangSmith 会自动记录每一次调用的完整执行链
- 测试与评估:可以通过创建测试集来完成你应用的自动化测试,提升应用的质量
- 监控与可观测性:提供持续观察应用的监控情况的能力
- Prompt 版本管理与协作:可以管理 Prompt 模板以及对 Prompt 进行版本控制
LangSmith 的接入非常简单,如下:
(1)、申请 API Key
登录 https://smith.langchain.com 申请 API Key。
(2)、代码中接入
python
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "lsv2_pt_xxxx"
# LangSmith 项目名称,默认 default
os.environ["LANGCHAIN_PROJECT"] = "default"再运行程序,就可以看到具体的调用过程,如下:
3.借助 LangGraph 实现 ReAct Agent
(1)目标
实现 ReAct Agent,可以根据用户输入进行思考,循环调用工具直到有足够的信息来解决用户的输入。
比如:
- User:帮我修改 payment 的工作负载,镜像为 nginx:v1.0
- Assistant:需要修改 payment 工作负载,首先需要获取 payment deployment
- Assistant:先调用 tools:get_deployment 获取工作负载
- Assistant:获取成功,再调用 tools:patch_deployment 修改工作负载
- Assistant:修改成功
(2)如何控制循环
需要借助 add_conditional_edges 实现动态控制,当条件函数返回 tools 字符串,则继续调用 tools 节点,当返回 __end__ 字符串,则退出。
伪代码如下:
python
def should_continue(state: MessagesState) -> Literal["tools", "__end__"]:
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return "__end__"
workflow.add_conditional_edges(
"chat",
should_continue,
)(3)核心实现
1.安装依赖包
bash
pip install -U langgraph langchain-openai2.引入依赖包
python
from langchain_openai import ChatOpenAI
from typing import Literal
from langchain_core.tools import tool
from IPython.display import Image, display
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph, MessagesState
# 尝试导入 matplotlib,如果不可用则设置标志
try:
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from io import BytesIO
MATPLOTLIB_AVAILABLE = True
except ImportError:
MATPLOTLIB_AVAILABLE = False3.定义 tools
python
@tool
def get_deployment(deplyment_name: str):
"""Use this to get deployment YAML."""
print("get deployment: ", deplyment_name)
return """
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment
spec:
selector:
matchLabels:
app: payment
template:
metadata:
labels:
app: payment
spec:
containers:
- name: payment
image: nginx
ports:
- containerPort: 80
"""
@tool
def apply_deployment(patch_json: str):
"""Edit the deployment YAML."""
print("apply deployment: ", patch_json)
# 这里在后续的课程里会讲解调用 k8s API 来真正部署 patch_json
return "deployment applied"这两个 tools 是伪代码,主要实现获取 deployment 和生成 deployment。
4.创建 Graph
python
def call_model(state: MessagesState):
"""调用 LLM 模型处理用户消息
这个函数是工作流的核心节点,负责:
1. 接收用户的自然语言请求
2. 分析请求并决定是否需要调用工具
3. 生成响应或工具调用指令
Args:
state: 包含消息历史的状态对象
Returns:
dict: 包含模型响应的状态更新
"""
messages = state["messages"]
response = model_with_tools.invoke(messages)
return {"messages": [response]}
def should_continue(state: MessagesState) -> Literal["tools", "__end__"]:
"""决定工作流的下一步行动
这个函数检查最后一条消息是否包含工具调用:
- 如果包含工具调用,则转到工具执行节点
- 如果不包含,则结束对话
Args:
state: 包含消息历史的状态对象
Returns:
str: 下一个节点的名称("tools" 或 "__end__")
"""
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return "__end__"
# 声明 tools 变量
tools = [get_deployment, apply_deployment]
model_with_tools = ChatOpenAI(
model="gpt-4o",
api_key="sk-xxxx",
base_url="https://vip.apiyi.com/v1",
temperature=0
).bind_tools(tools)
# 将 tools 转换成 node 节点,有多少个 tools 就有多少个 node 节点
tool_node = ToolNode(tools)
workflow = StateGraph(MessagesState)
workflow.add_node("chat", call_model)
workflow.add_node("tools", tool_node)
# 定义工作流的边和条件
workflow.add_edge("__start__", "chat")
# 动态控制是否继续运行 tools 或者退出
workflow.add_conditional_edges(
"chat",
should_continue,
)
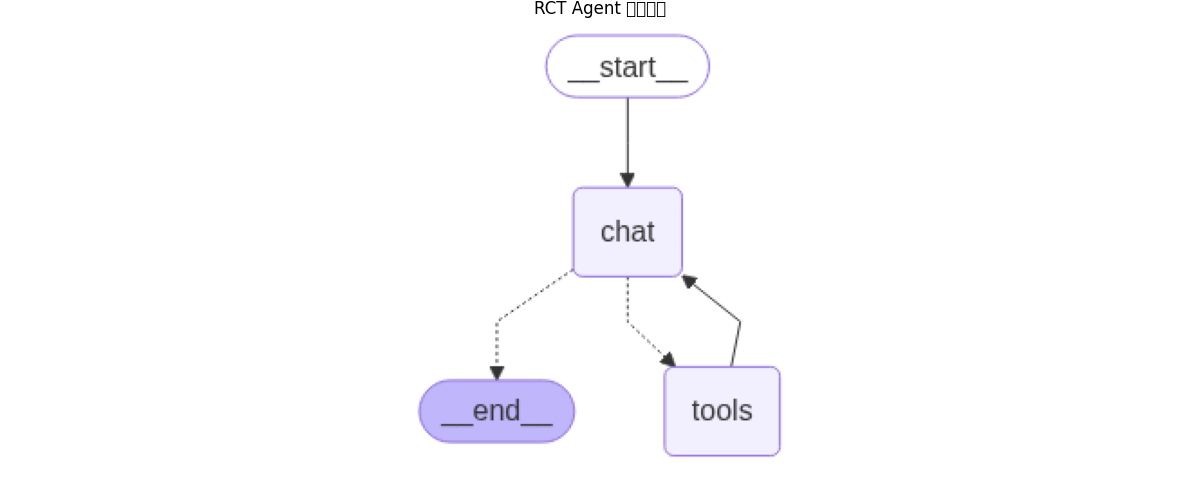
# 定义有向有环图
workflow.add_edge("tools", "chat")
app = workflow.compile()
print("🚀 正在启动 RCT Agent...")
print("📊 生成工作流程图...")
try:
# 获取图形的 PNG 数据
png_data = app.get_graph().draw_mermaid_png()
# 保存图形到文件,方便用户查看工作流结构
with open('rct_workflow_graph.png', 'wb') as f:
f.write(png_data)
print("✅ 工作流图已保存为 'rct_workflow_graph.png'")
# 尝试使用 matplotlib 在新窗口中显示图形
if MATPLOTLIB_AVAILABLE:
try:
# 将 PNG 数据转换为图像并显示
img = mpimg.imread(BytesIO(png_data))
plt.figure(figsize=(12, 8))
plt.imshow(img)
plt.axis('off')
plt.title('RCT Agent 工作流图')
plt.tight_layout()
plt.show()
print("🖼️ 工作流图已在新窗口中显示")
except Exception as e:
print(f"⚠️ 无法在窗口中显示图形: {e}")
print("💡 请查看保存的 'rct_workflow_graph.png' 文件")
else:
print("💡 matplotlib 不可用,请查看保存的 'rct_workflow_graph.png' 文件")
print("💡 要在窗口中显示图形,请安装: pip install matplotlib")
except Exception as e:
print(f"❌ 生成工作流图时出错: {e}")
print("💡 请确保已安装 graphviz: pip install graphviz")
for chunk in app.stream(
{"messages": [("human", "帮我修改 payment 的工作负载,镜像为 nginx:v1.0")]}, stream_mode="values"
):
chunk["messages"][-1].pretty_print()5.测试
生成的图如下:
测试的内容如下:
text
============================================================
🤖 RCT Agent 演示:修改 payment 部署的镜像版本
============================================================
📝 用户请求:帮我修改 payment 的工作负载,镜像为 nginx:v1.0
------------------------------------------------------------
================================ Human Message =================================
帮我修改 payment 的工作负载,镜像为 nginx:v1.0
================================== Ai Message ==================================
Tool Calls:
get_deployment (call_N8eflW7bpaL3wgw7YlqfZLDT)
Call ID: call_N8eflW7bpaL3wgw7YlqfZLDT
Args:
deplyment_name: payment
正在获取部署配置: payment
================================= Tool Message =================================
Name: get_deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment
spec:
selector:
matchLabels:
app: payment
template:
metadata:
labels:
app: payment
spec:
containers:
- name: payment
image: nginx
ports:
- containerPort: 80
================================== Ai Message ==================================
Tool Calls:
apply_deployment (call_3PboJyk8X9TwIYtSGgwp5isC)
Call ID: call_3PboJyk8X9TwIYtSGgwp5isC
Args:
patch_json: {"spec": {"template": {"spec": {"containers": [{"name": "payment", "image": "nginx:v1.0"}]}}}}
正在应用部署补丁: {"spec": {"template": {"spec": {"containers": [{"name": "payment", "image": "nginx:v1.0"}]}}}}
================================= Tool Message =================================
Name: apply_deployment
部署补丁已成功应用
================================== Ai Message ==================================
已成功将 `payment` 工作负载的镜像更新为 `nginx:v1.0`。如有其他需求,请随时告知!
============================================================
✅ RCT Agent 演示完成!
💡 Agent 已成功处理 Kubernetes 部署修改请求
============================================================通过打印的日志可以看到调用了两次 tool,分别是 get_deployment 和 apply_deployment,这就实现了循环调用的效果了。
4. LangGraph 的并行实践
在 LangGraph 中还有一个重要的特性就是并行,用于控制和理解每个步骤运行完毕后的流程。
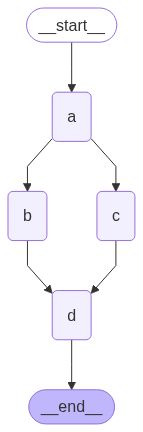
通过一个简单例子说明,定义了 A、B、C 三个节点,其中 B 和 C 在 A 运行后并行,形成两条分叉路径,最终汇聚到 D 节点。代码如下:
python
import operator
from typing import Annotated, Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
# The operator.add reducer fn makes this append-only
aggregate: Annotated[list, operator.add]
class ReturnNodeValue:
def __init__(self, node_secret: str):
self._value = node_secret
def __call__(self, state: State) -> Any:
print(f"Adding {self._value} to {state['aggregate']}")
return {"aggregate": [self._value]}
builder = StateGraph(State)
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_edge(START, "a")
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
graph.invoke({"aggregate": []}, {"configurable": {"thread_id": "foo"}})输出图如下:
输出日志如下:
text
{'aggregate': ["I'm A", "I'm B", "I'm C", "I'm D"]}通过日志发现 D 只被执行了一次,这体现了并行下的流程控制。
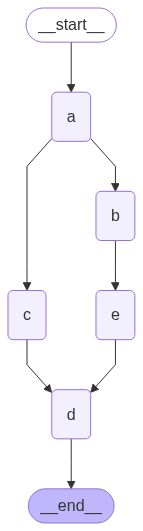
但是,如果我们在 B 的下游再加一个节点,就会出现不一样的效果,如下:
python
import operator
from typing import Annotated, Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
# The operator.add reducer fn makes this append-only
aggregate: Annotated[list, operator.add]
class ReturnNodeValue:
def __init__(self, node_secret: str):
self._value = node_secret
def __call__(self, state: State) -> Any:
print(f"Adding {self._value} to {state['aggregate']}")
return {"aggregate": [self._value]}
builder = StateGraph(State)
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_edge(START, "a")
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
builder.add_node("e", ReturnNodeValue("I'm E"))
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "e")
builder.add_edge("c", "d")
builder.add_edge("e", "d")
builder.add_edge("d", END)
graph = builder.compile()
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
graph.invoke({"aggregate": []}, {"configurable": {"thread_id": "foo"}})图如下:
输出的日志:
text
{'aggregate': ["I'm A", "I'm B", "I'm C", "I'm D", "I'm E", "I'm D"]}通过日志可以看到 D 被执行了 2 次,这说明新增路径会影响最终的执行次数。
- B 和 C 处于同一并行级别,而 D 由于后续分岔节点数量不一致,被分为两个不同的 super-step
- 当 C 运行完后会通知执行 D 一次;同样,当 E 运行完后会通知执行 D 一次,所以整个流程中 D 会被执行 2 次
但是,在 LangGraph 中,一个 super-step 内的节点只会运行一次,这意味着并行操作需要在这一框架下进行优化,以确保每个节点只运行一次。为了实现既并行又只运行一次的目标,可以通过将 C 和 E 视为一个整体,并在它们之后紧跟 D 的方式,将 C 和 E 封装起来,从而确保 D 仅在 C 和 E 都完成时运行一次。
在代码中,我们只需要做如下修改:
python
# 注释下面这两行
#builder.add_edge("c", "d")
#builder.add_edge("e", "d")
# 将C和E当成一个节点
builder.add_edge(["c", "e"], "d")这样修改之后,D 就只输出一次,如下:
text
{'aggregate': ["I'm A", "I'm B", "I'm C", "I'm E", "I'm D"]}从零开发个人运维知识库 Agent
1.为什么需要运维知识库 Agent
- 利用 LangGraph 技术构建个人运维知识库,作为个人在数字领域的运维分身,以实现自动化解答功能。
- 个人运维知识库能够回答业务方提出的常规问题,减轻个人在处理基础询问上的负担。
- 通过沉淀个人知识库,可以创建一个数字分身,为业务方提供无需人工干预的服务。
- 强调个人知识库的重要性,它能帮助解答那些不必亲自思考的问题,提升工作效率。
2.运维知识库 Agent 的实现方式
结合目前的业内实践,主要有以下三种实现方式:
- 使用自托管服务,无需代码开发,代表有:QAnything、RAGFlow、Open Web UI
- SAAS 服务,代表有:Coze、Dify
- 二次开发,代表有:LangChain、LangGraph
第 1、第 2 中实现方式比较简单,这里主要介绍第三种实现方式:使用 LangGraph 实现运维知识库 Agent。
3.利用 Web Search + 自适应 RAG Agent 实现运维知识库
(1)流程梳理
- 定义一个路由器来识别问题,判断是从知识库检索还是从网络搜索
- 当问题属于知识库检索,则使用自适应 RAG 进行回答
- 当问题属于网络搜索,则使用 Tavily 进行搜索回答
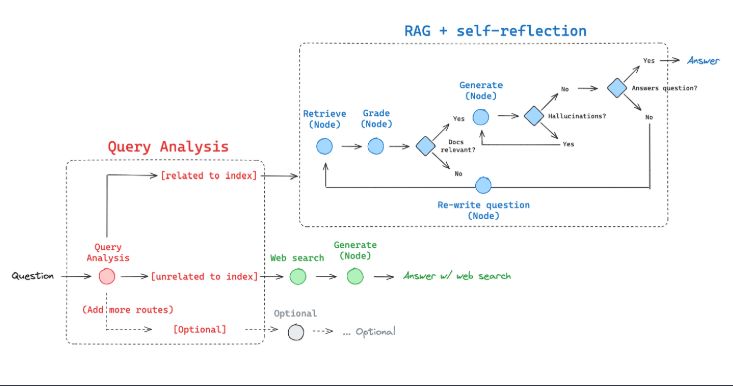
需要注意的是,在使用 自适应 RAG 的时候:
1.自适应 RAG Agent 在匹配到相关知识块后,不直接问答,而是先判断匹配块与问题的相关性,再由大模型生成答案,并评估答案的有效性和准确性。
2.如果向量检索出的文档与问题不匹配,系统会重写问题,基于语义重新进入向量检索阶段,确保问题能得到有效解答。
(2)、使用 LangChain 构造自适应 RAG
a.安装依赖包
bash
pip install -U langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraphb.将知识库向量化
python
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import MarkdownHeaderTextSplitter
import uuid
import os
file_path = os.path.join('data', 'data.md')
with open(file_path, 'r', encoding='utf-8') as file:
docs_string = file.read()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
doc_splits = text_splitter.split_text(docs_string)
# Add to vectorDB
random_directory = "./" + str(uuid.uuid4())
embedding = OpenAIEmbeddings(
model="text-embedding-3-small",
openai_api_key="sk-xxx",
openai_api_base="https://vip.apiyi.com/v1",
)
vectorstore = Chroma.from_documents(documents=doc_splits, embedding=embedding, persist_directory=random_directory, collection_name="rag-chroma",)
retriever = vectorstore.as_retriever()c.判断问题是否和知识库相关
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
# 温度0,不需要输出多样性
llm = ChatOpenAI(
model="gpt-4o-mini",
api_key="sk-xxxx",
base_url="https://vip.apiyi.com/v1",
temperature=0
)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt
system = """您是一名评分员,负责评估检索到的文档与用户问题的相关性。\n
测试不需要很严格。目标是过滤掉错误的检索。\n
如果文档包含与用户问题相关的关键字或语义含义,则将其评为相关。\n
给出二进制分数“yes”或“no”,以指示文档是否与问题相关。"""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
# 相关问题
question = "payment_backend 服务是谁维护的"
# 不相关问题
#question = "深圳天气"
docs = retriever.get_relevant_documents(question)
# 观察每一个文档块的相关性判断结果
for doc in docs:
print("doc: \n", doc.page_content, "\n")
print(retrieval_grader.invoke({"question": question, "document": doc.page_content}))
print("\n")d.生成回复
python
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(
model="gpt-4o-mini",
api_key="sk-xxxx",
base_url="https://vip.apiyi.com/v1",
temperature=0
)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)e.判断回复是否基于知识库事实
python
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(
model="gpt-4o-mini",
api_key="sk-xxx",
base_url="https://vip.apiyi.com/v1",
temperature=0
)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Prompt
system = """您是一名评分员,正在评估 LLM 生成是否基于一组检索到的事实/由一组检索到的事实支持。\n
给出二进制分数“yes”或“no”。 “yes”表示答案基于一组事实/由一组事实支持。"""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"documents": docs, "generation": generation})f.评估答案的准确性
python
# Data model
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(
model="gpt-4o-mini",
api_key="sk-xxxx",
base_url="https://vip.apiyi.com/v1",
temperature=0
)
structured_llm_grader = llm.with_structured_output(GradeAnswer)
# Prompt
system = """您是评分员,评估答案是否解决某个问题 \n
给出二进制分数“yes”或“no”。“yes”表示答案解决了问题。"""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"question": question, "generation": generation})g.如果不准确,结合知识库重写问题
python
llm = ChatOpenAI(
model="gpt-4o-mini",
api_key="sk-xxx",
base_url="https://vip.apiyi.com/v1",
temperature=0
)
# Prompt
system = """您有一个问题重写器,可将输入问题转换为针对 vectorstore 检索进行了优化的更好版本 \n
。查看输入并尝试推断底层语义意图/含义,使用用户语言回复。"""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})(3)使用 LangGraph 构造 Agent
a.定义 GraphState 类
python
from typing import List
from typing import Literal
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]b.定义节点
python
### Nodes 节点
# 检索文档
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
# 生成回复
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
# 判断检索到的文档是否和问题相关
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("----检查文档是否和问题相关----\n")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("文档和用户问题相关\n")
filtered_docs.append(d)
else:
print("文档和用户问题不相关\n")
continue
return {"documents": filtered_docs, "question": question}
# 改写问题,生成更好的问题
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("改写问题\n")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
print("LLM 改写优化后更好的提问:", better_question)
return {"documents": documents, "question": better_question}
### Edges
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("访问检索到的相关知识库\n")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print("所有的文档都不相关,重新生成问题\n")
return "transform_query"
else:
# We have relevant documents, so generate answer
print("文档和问题相关,生成回答")
return "generate"
# 评估生成的回复是否基于知识库事实(是否产生了幻觉)
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("评估生成的回复是否基于知识库事实(是否产生了幻觉)\n")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("生成的回复是基于知识库,没有幻觉\n")
# 最后检查回答是否解决了问题
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("问题得到解决\n")
return "useful"
else:
print("问题没有得到解决\n")
return "not useful"
else:
print("生成的回复不是基于知识库,继续重试……\n")
return "not supported"
# 问题分流路由器:将问题分流到 Self-RAG 或者搜索引擎
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vectorstore", "web_search"] = Field(
...,
description="Given a user question choose to route it to web search or a vectorstore.",
)
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
llm =ChatOpenAI(
model="gpt-4o-mini",
api_key="sk-xxxx",
base_url="https://vip.apiyi.com/v1",
temperature=0
)
structured_llm_router = llm.with_structured_output(RouteQuery)
# Prompt
system = """您是将用户问题路由到 vectorstore 或 web_search 的专家。
vectorstore 包含运维、工单、微服务、网关、工作负载、日志等相关内容,使用 vectorstore 来回答有关这些主题的问题。
否则,请使用 web_search"""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
question_router = route_prompt | structured_llm_router
print("---开始分流问题---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "web_search":
print("---问题分流到网络搜索---")
return "web_search"
elif source.datasource == "vectorstore":
print("---问题分流到知识库向量检索---")
return "vectorstore"
### Search
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.schema import Document
web_search_tool = TavilySearchResults(k=3)
# 网络搜索
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---进行网络搜索---")
question = state["question"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
return {"documents": web_results, "question": question}c.构建 Graph
python
from langgraph.graph import END, StateGraph, START
from IPython.display import Image, display
workflow = StateGraph(GraphState)
# 添加 Nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # 检索文档
workflow.add_node("grade_documents", grade_documents) # 判断检索到的文档是否和问题相关
workflow.add_node("generate", generate) # 生成回复
workflow.add_node("transform_query", transform_query) # 改写问题,生成更好的问题
# 定义有向有环图
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
# 给 grade_documents 添加条件边,判断 decide_to_generate 函数返回的结果
# 如果函数返回 "transform_query",则跳转到 transform_query 节点
# 如果函数返回 "generate",则跳转到 generate 节点
workflow.add_conditional_edges(
"grade_documents",
# 条件:评估检索到的文档是否和问题相关,如果不相关则重新检索,如果相关则生成回复
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
# 给 generate 添加条件边,判断 grade_generation_v_documents_and_question 函数返回的结果
# 如果函数返回 "useful",则跳转到 END 节点
# 如果函数返回 "not useful",则跳转到 transform_query 节点
# 如果函数返回 "not supported",则跳转到 generate 节点
workflow.add_conditional_edges(
"generate",
# 条件:评估生成的回复是否基于知识库事实(是否产生了幻觉),是则评估答案准确性,否则重新生成问题
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()
try:
display(Image(app.get_graph().draw_mermaid_png()))
except Exception:
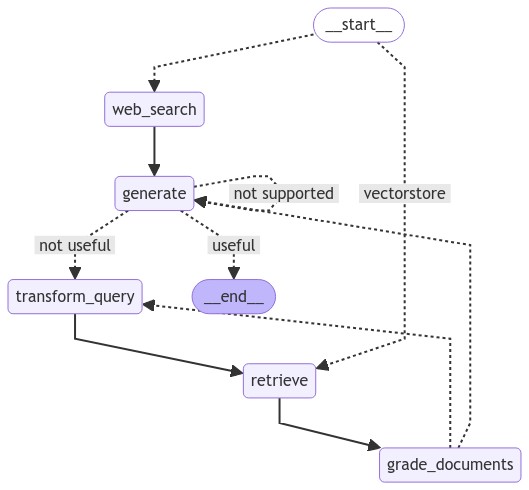
pass构建后的图为:
d.测试
python
from pprint import pprint
# 向量匹配问题
#inputs = {"question": "谁管理的服务数量最多?"}
# 搜索问题
inputs = {"question": "深圳最近的新闻"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])会根据不同的问题自适应不同的处理办法。
总结
综上,本文围绕基于大模型构建智能体 Agent 展开了全面且深入的阐述,从 Agent 的核心定义、核心能力与模块构成,到四种主流设计模式的特点与适用场景,再到从零开发 Agent 的具体实践(包括 RAG Agent 的实现与优化),以及经典 Translation Agent 的源码架构分析,均进行了细致解读。
尤为关键的是,通过 LangGraph 这一工具,展示了如何更高效地构建 Agent,从单节点基础功能到复杂的多节点协作、循环调用与并行处理,清晰呈现了 LangGraph 在流程建模上的优势。最后,结合运维场景,实战演示了个人运维知识库 Agent 的实现,融合了自适应 RAG 与网络搜索,体现了 Agent 在实际业务中的应用价值。
总体而言,Agent 作为大模型延伸能力的重要载体,凭借其自主思考、工具调用与记忆能力,正在诸多领域展现出强大的潜力。而 LangGraph 等工具的出现,进一步降低了复杂 Agent 的开发门槛,为开发者构建更智能、更灵活的 AI 应用提供了有力支撑。未来,随着技术的不断演进,Agent 有望在自动化处理复杂任务、提升人机交互效率等方面发挥更加重要的作用。