
.png)
AIOps系列 | 大模型入门实战
✍ 道路千万条,安全第一条。操作不规范,运维两行泪。
最近在学习《AIOps》相关的知识课程,为了让学习有一定的收获,所以将其进行了总结分享,如果你恰好也需要,很荣幸能帮到你。
AIOps 的实现离不开现在大模型的大力发展,所以要做 AIOps 相关的业务,就需要了解并使用大模型相关知识。本次内容将从以下6个章节介绍大模型相关的知识。
- Prompt Engineering
- Chat Completions、Memory、JSON Mode
- Function Calling
- Fine-tuning
- 检索增强生成(RAG、Graph RAG)
- 本地部署常见的开源模型
Prompt Engineering
Prompt简介
Prompt Engineering 是指通过设计、优化输入给 AI 模型的“提示词”(Prompt),来引导模型生成更准确、有用或创意性输出的技术。它是一门结合语言理解、任务建模与人机交互的艺术与科学。
尽管现在的大模型具备强大的自然语言理解和生成能力,但它的行为高度依赖输入的提示词(Prompt),所以 Prompt 决定着大模型的输出质量。
当用户输入 Prompt,大模型接受到的其实是一个个 Token,这是为什么呢?
在大模型中,Token 是模型处理文本的基本单位,人类是通过文本来理解内容,而大模型是通过 Token 来理解内容。它可以是一个单词、标点符号、数字,甚至是一个子词(subword)。不同模型对 Token 的划分方式略有不同,但总体上可以理解为:把一段文字切分成一小块一小块的“单元”就是 Token 。
比如,当用户输入 "Hello, world!",会被拆分为以下几个 Token(以 GPT 模型为例):
- "Hello"
- ","
- " world"
- "!"
所以一共是 4 个 token 。
当大模型接收 Token 后,会根据这些 Token 进行推理生成新的 Token,最后再把这些 Token 转换成人类可读的文本输出。
Tips:每个模型都有最大上下文长度限制(比如 GPT-3.5 是 4096 tokens,GPT-4 可达 32768 tokens),包括你的 Prompt + 输出内容都不能超过这个限制。
另外,目前商用大模型的Token免费额度都有限,如果设计的Prompt不合理,就会产生额外的费用,我们可以看看Prompt中的哪些内容对Token的数量有实质的影响。
| 类型 | 影响程度 | 说明 |
|---|---|---|
| 文字长度 | ⬆️ 高 | 内容越长,Token 越多 |
| 标点符号 | ⬆️ 中 | 逗号、句号、引号等都会单独算作 Token |
| 专业术语/生僻词 | ⬆️ 中 | 某些模型可能将其拆成多个 Token |
| 语言种类 | ⬆️ 中 | 英语通常比中文 Token 更少 |
| 编程语言 | ⬆️ 高 | 特殊符号多,Token 数量上升快 |
所以,我们在设计Prompt的时候要记住 并非输入的越多,回答的就越好 。要记住设计 Prompt 的几个核心原则:
- 具体描述,避免模糊:不说 “不要遗漏重点”,而是明确 “请突出 XX、XX 两个关键信息”;
- 排序重要事项:如果有多个需求,按优先级说明,比如 “首先分析日志错误,其次统计出现频率,最后给出解决方案”;
- 使用标准格式:比如用 Markdown 的标题、列表等结构,让模型输出更规整,例如 “请用 ### 问题原因、### 解决步骤的格式整理结果”;
- 拆解任务,给出思路:复杂问题分步骤引导,比如 “先分析错误类型,再匹配历史案例,最后生成修复建议”。
Prompt的开发模式
Zero-shot和Few-shot
日常工作中,常用的Prompt编写模式是 Zero-shot 和 Few-shot。其中,Zero-shot 模式是纯自然的描述任务,不提供具体的例子,比如仅说明识别用户意图可能涉及查询日志、指标或运维操作。而 Few-shot 模式在自然语言任务描述之外,提供参考例子,如给出三个示例,以增强大模型的推理准确性。
由于 Few-shot 模式会给大模型提供例子,这能使大模型回答的更加精准, 所以在日常使用中,我们优先采用 Few-shot 模式。
但是,对于处理逻辑性比较强的任务时,单纯 Few-shot 不太够用,这时候就要引入 思维链(Chain of Thought)。
Chain of Thought
思维链是一种技巧,旨在让大模型在给出答案前进行逐步思考,并在每一步提供解释,以增强答案的解释性和提高推理的准确性。
一个典型的 CoT Prompt 包括以下几个部分:
- 问题描述
- 明确要求分步思考
- 示例演示(可选)
- 最终要求输出答案
比如以下Prompt:
问题:小明有 5 个苹果,吃了 2 个,又买了 3 个。他现在有多少个苹果?
请一步步思考这个问题,并写出你的推理过程,最后给出答案。
大模型可能的回答是:
第一步:小明最开始有 5 个苹果。
第二步:他吃了 2 个,剩下 5 - 2 = 3 个。
第三步:他又买了 3 个,所以现在有 3 + 3 = 6 个苹果。
答:小明现在有 6 个苹果。
在运维场景中,可以把专家知识库中的内容加入到系统提示语中,让大模型扮演运维专家的角色,优先以提供的知识库而非自身训练的内容回答问题,这种基于特定知识库进行问题解答可以提升回答的准确性和专业性。
另外,在处理大文本的时候,一个Prompt由于有上下文限制导致无法完整输入,这时候我们可以考虑为 Prompt 进行分片。
Prompt 分片
Prompt 分片是指将原始 Prompt 切分为多个小块(chunks),然后分别处理这些小块内容,并最终整合输出结果的一种策略。
它常用于以下场景:
- 输入文本太长,超过模型最大 Token 数限制(如 GPT-3.5 的 4096、GPT-4 的 8192 / 32768)
- 需要对文档、文章、日志等内容进行摘要、分析、问答等操作
- 提高模型对长文本的理解和处理能力
Prompt分布的工作流程是:
- 拆分:将长文本按一定规则拆分成多个chunk
- 处理:对每个chunk进行单独运行Prompt,生成中间结果
- 整合:将所有中间结果合并,生成最终的输出
常见的分片方式有:
| 分片方法 | 描述 | 适用场景 |
|---|---|---|
| 固定长度分片 | 每个 chunk 固定 Token 数量(如 1000 tokens) | 文本较长且结构不敏感的任务 |
| 基于语义分片 | 根据句子、段落、章节等自然语言结构进行划分 | 需要保留逻辑结构的任务(如论文、合同) |
| 滑动窗口分片 | 前后 chunk 有部分重叠,避免信息丢失 | 关键信息可能跨 chunk 出现的场景 |
| 结合 RAG 使用的向量化分片 | 使用 Embedding 向量匹配最相关的 chunk 输入模型 | 检索增强生成(RAG)、问答系统 |
不过,在使用 Prompt 分片的时候需要注意:
- 信息丢失风险:分片可能导致上下文断裂,影响模型的理解导致信息丢失。
- Token成本增加:分片会多次调用模型的API,每次调用都会消耗Token,导致成本的增加。
- 一致性问题:不同的chunk的输出可能存在矛盾,需要后期整合校正。
Chat Completions、Memory、JSON Mode
Chat Completions
Chat Completions(聊天补全) 是现代大语言模型(如 OpenAI 的 GPT-3.5、GPT-4、通义千问、Claude 等)提供的一种 API 接口,专门用于处理多轮对话任务。
它与传统的 Completions 不同,支持更自然的对话上下文建模,能记住历史对话内容,并根据上下文生成连贯的回复。
Chat Completions 主要包含 输入 和 输出 两个核心的结构:
- 输入:一个包含角色、内容的消息列表
{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "system", "content": "你是一个翻译助手,擅长中英文互译。"},
{"role": "user", "content": "请将以下中文翻译成英文:'人工智能是未来的关键技术之一。'"},
{"role": "assistant", "content": "'Artificial intelligence is one of the key technologies of the future.'"},
{"role": "user", "content": "谢谢!"}
],
"temperature": 0.7
}
- 输出:模型生成的回复
{
"choices": [
{
"message": {
"role": "assistant",
"content": "不客气!如果你还有需要翻译的内容,请随时告诉我。"
}
}
]
}
从上面的例子可以看到 Chat Completions 有三大角色:
- system:系统指令,用于设定 AI 的行为、身份或任务规则。通常只在对话开始时出现一次。
- user:用户输入,代表用户说的话或提问。
- assistant:模型输出,即 AI 的回答。
下面我们使用 python 来开发一个简单的 Chat Completions。
(1)安装 OpenAI python包
pip install --upgrade openai
(2)开发代码
from openai import OpenAI
client = OpenAI(
api_key="sk-xxxx",
base_url="https://api.siliconflow.cn/v1",
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
messages=[
{"role": "system", "content": "你是一个运维专家,你可以帮忙解决专业的技术运维问题"},
{"role": "user", "content": "如何在Ubuntu上安装Python3,请用一句话总结"}
]
)
print(completion.choices[0].message.content)
Tips:由于网络原因,这里使用的 硅基流动 的地址。
(3)执行代码,获取输出
PS E:\workspace\python\aiops\chat-completions> python .\main.py
运行 sudo apt install python3 即可安装Ubuntu上的Python3
但是,大模型的推理过程本质上是发起一次 HTTP 请求,由于 HTTP请求是无状态的,所以每次推理都是独立的。
如果要让大模型能基于之前的内容进行对话,就需要将上次推理的输出作为下次请求的message参数以实现记忆能力。
如下:
from openai import OpenAI
client = OpenAI(
api_key="sk-xxxx",
base_url="https://api.siliconflow.cn/v1",
)
message = [
{"role": "system", "content": "你是一个运维专家,你可以帮忙解决专业的技术运维问题"}
]
while True:
user_input = input("请输入问题:")
message.append({"role": "user", "content": user_input})
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
messages=message
)
message.append({"role": "assistant", "content": completion.choices[0].message.content})
print(completion.choices[0].message.content)
这样在重复对话的场景中,就能基于上下文做继续的回答。
LangChain Memory
在处理大模型记忆的时候,直接管理上下文较为复杂,因为大模型由于Token的限制无法记住所有的对话,这里就可以引入 LangChain 这种长期记忆的管理方法。
LangChain 提供了多种类型的 Memory,适用于不同场景:
| 类型 | 名称 | 描述 | 是否持久化 |
|---|---|---|---|
✅ConversationBufferMemory | 缓冲记忆 | 将对话历史缓存在内存中,按顺序存储所有消息 | ❌ 不持久化 |
✅ConversationBufferWindowMemory | 窗口记忆 | 只保留最近 N 条对话记录,避免 Token 过多 | ❌ 不持久化 |
✅ConversationTokenBufferMemory | Token 缓冲记忆 | 根据总 Token 数限制来截断历史消息 | ❌ 不持久化 |
✅ConversationSummaryMemory | 摘要记忆 | 自动将历史对话总结为一段摘要,节省 Token | ❌ 不持久化 |
✅ConversationKGMemory | 知识图谱记忆 | 提取对话中的实体关系,构建知识图谱 | ❌ 不持久化 |
✅RedisChatMessageHistory+ 自定义 | Redis / DB 记忆 | 使用数据库(如 Redis、PostgreSQL)持久化保存历史记录 | ✅ 支持持久化 |
下面我们使用 ConversationBufferMemory 来写一个简单的例子:
(1)先安装langchain包
pip install langchain langchain_openai --upgrade
(2)开发代码
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_core.messages import SystemMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate(
[
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{text}"),
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
llm = ChatOpenAI(
openai_api_key="sk-xxx",
base_url="https://api.siliconflow.cn/v1",
model_name="deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
max_tokens=None,
timeout=None,
)
legacy_chain = LLMChain(
llm=llm,
prompt=prompt,
memory=memory,
)
while True:
user_input = input("请输入问题:")
response = legacy_chain.invoke({"text": user_input})
print(response)
Tips:不同的langchain版本使用方式会不一样。
从LangChain v0.3版本开始,官方推荐使用LangGraph来处理记忆和状态管理,原因如下:
- 多用户和多会话支持 - LangGraph原生支持多用户和多会话场景,这是实际应用中的常见需求
- 保存和恢复对话 - 能够在任何时间点保存和恢复复杂对话,有助于错误恢复和人工干预
- 更好的兼容性 - 与传统语言模型和现代聊天模型完全兼容,早期的记忆实现在处理新的聊天模型API时会出现问题
- 高度可定制 - 允许完全控制记忆的工作方式,并使用不同的存储后端
其使用方式为:
(1)安装依赖包
pip install langchain langchain-openai langgraph
(2)开发代码
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langgraph.graph import END, StateGraph
from typing import Dict, List, Annotated, TypedDict
# 定义状态类型
class ChatState(TypedDict):
messages: List[Annotated[HumanMessage | AIMessage, "消息历史"]]
next: str
# 加载环境变量
import os
from dotenv import load_dotenv
import sys
# 尝试加载.env文件中的环境变量
load_dotenv()
def setup_environment():
"""设置环境并初始化LLM
Returns:
tuple: (llm, is_valid) - LLM实例和环境是否有效的标志
"""
# 初始化LLM
llm = ChatOpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY","sk-htiyofqoslaxhcdxrqvnedlvbtezbvuwtpttefvllbdssiiv"),
base_url=os.getenv("API_BASE_URL", "https://api.siliconflow.cn/v1"),
model_name=os.getenv("MODEL_NAME", "deepseek-ai/DeepSeek-R1-0528-Qwen3-8B"),
max_tokens=None,
timeout=None,
)
return llm, True
# 设置环境并获取LLM
llm, is_valid_env = setup_environment()
# 创建提示模板
prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="messages"),
]
)
# 定义处理用户输入的函数
def user_input(state: ChatState, config: dict) -> ChatState:
"""处理用户输入并更新状态
Args:
state: 当前状态
config: 配置参数,包含user_message
Returns:
更新后的状态
"""
# 从config中获取用户消息
user_message = config["configurable"]["user"]["user_message"]
# 添加用户消息到历史
new_messages = state["messages"] + [HumanMessage(content=user_message)]
return {"messages": new_messages, "next": "assistant"}
# 定义生成助手回复的函数
def assistant_response(state: ChatState) -> ChatState:
"""生成助手回复并更新状态"""
# 使用LLM生成回复
response = llm.invoke(state["messages"])
# 添加助手回复到历史
new_messages = state["messages"] + [response]
return {"messages": new_messages, "next": END}
# 创建状态图
workflow = StateGraph(ChatState)
# 添加节点
workflow.add_node("user", user_input)
workflow.add_node("assistant", assistant_response)
# 设置边
workflow.set_entry_point("user")
workflow.add_edge("user", "assistant")
# 编译图
app = workflow.compile()
# 主循环
def main():
# 检查环境是否有效
if not is_valid_env:
print("错误: 环境设置无效,程序无法继续。请解决上述问题后重试。")
exit(1)
# 初始化状态
state = {"messages": [], "next": ""}
print("聊天助手已启动,输入 'exit' 退出")
while True:
user_message = input("请输入问题:")
if user_message.lower() in ["exit", "quit", "q", "退出"]:
print("感谢使用,再见!")
break
# 运行工作流
try:
# 创建输入字典,包含用户消息
# 在LangGraph中,需要通过configurable参数传递给节点函数
inputs = {"user_message": user_message}
# 调用工作流,通过config.configurable.user传递参数给user节点
state = app.invoke(state, config={"configurable": {"user": inputs}})
# 打印最新的助手回复
print(f"\n{state['messages'][-1].content}\n")
except Exception as e:
print(f"\n处理您的问题时出错: {str(e)}\n请尝试重新提问或联系管理员。\n")
if __name__ == "__main__":
main()
其达到的效果一样。
JSON Mode
在日常的开发过程中,常用 JSON 做前后端交互的方式,那在使用大模型的过程中,也可以要求大模型稳定输出为 JSON 格式的数据,这样方便我们用这些数据做更多的扩展。
一个简单的示例如下:
from openai import OpenAI
client = OpenAI(
base_url="https://api.siliconflow.cn/v1",
api_key="sk-xxxx",
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": '你现在是一个 JSON 对象提取专家,请参考我的JSON定义输出JSON对象,示例:{"service_name":"","action":""},其中action可以是 get_log,restart,delete'},
{"role": "user", "content": "帮我重启pay服务"}
]
)
print(response.choices[0].message.content)
其输出为:
{"service_name":"pay","action":"restart"}
当然也可以使用 langchain 来实现,效果是一样的:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
# 定义期望的输出结构
class Person(BaseModel):
name: str = Field(description="name of the person")
age: int = Field(description="age of the person")
parser = JsonOutputParser(pydantic_model=Person)
prompt = ChatPromptTemplate.from_messages([
("system", "You are an AI that extracts structured data from text."),
("human", "Extract the person's name and age from this text: {text}\n{format_instructions}")
])
prompt = prompt.partial(format_instructions=parser.get_format_instructions())
model = ChatOpenAI(
openai_api_key="sk-xxx",
base_url="https://api.siliconflow.cn/v1",
model_name="deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
max_tokens=None,
timeout=None,
)
chain = prompt | model | parser
result = chain.invoke({"text": "John is 28 years old."})
print(result) # 输出: {'name': 'John', 'age': 28}
使用 JSON Mode 可以得到比较稳定的输出,但是这种 json 格式是相对固定的,对于较复杂的业务实现起来很难。在实际的业务场景中,通过会结合 Function Calling 来实现更复杂的业务。
Function Calling
Function Calling(函数调用) 是大型语言模型(LLM)的一项能力,允许模型根据用户的自然语言输入,识别并调用预定义的工具或 API 函数 ,从而执行特定任务。
它使得 AI 模型能够:
- 与外部系统交互(如数据库、API)
- 执行计算、查询数据、获取实时信息
- 做出基于工具返回结果的决策
Tips:它是构建智能代理(Agent)、自动化流程和增强型 AI 应用的关键技术。
它执行的基本流程是:
- 用户提问
- 模型识别意图
- 生成tool_call
- 执行函数调用
- 模型整合结果并输出
下面是 OpenAi 的简单示例:
from pydoc import cli
from openai import OpenAI
tools = [
{
"type": "function",
"function": {
"name": "get_curr_weather",
"description": "获取天气",
"parameters":{
"type": "object",
"properties":{
"location":{
"type":"string",
"description":"城市名称"
},
"unit":{
"type":"string",
"description":"单位"
}
}
},
"required": ["location"]
}
}
]
cli = OpenAI(
api_key="sk-xxxx",
base_url="https://vip.apiyi.com/v1",
)
response = cli.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "深圳天气怎么样"}
],
tools=tools,
tool_choice="auto"
)
print(response.choices)
Tips:这里换了一个模型地址,主要是有些模型不支持function call。
运行程序后的输出为:
[
Choice(finish_reason='tool_calls',
index=0,
logprobs=None,
message=ChatCompletionMessage(content=None,
refusal=None,
role='assistant',
annotations=None,
audio=None,
function_call=None,
tool_calls=[
ChatCompletionMessageToolCall(id='call_6m7LC4cHP8fuEcuugWwpFZsP',
function=Function(arguments='{
"location": "深圳"
}',
name='get_curr_weather',
parameters=None),
type='function')
]))
]
可以看到大模型识别到了 get_curr_weather 方法以及 "location": "深圳" 参数,接下来我们伪造一个 get_curr_weather 实际处理的方法,如下:
# 定义获取天气的函数
def get_curr_weather(location: str, unit: str = "摄氏度"):
"""获取当前天气"""
return f"{location}的天气是25{unit}"
# 处理模型的回复
try:
message = response.choices[0].message
# 检查是否有函数调用请求
if message.tool_calls:
# 获取函数调用信息
tool_call = message.tool_calls[0] # 获取第一个工具调用(可能有多个)
function_name = tool_call.function.name
try:
# 使用json.loads安全地解析函数参数
function_args = json.loads(tool_call.function.arguments)
print(f"\n函数调用请求: {function_name}")
print(f"函数参数: {function_args}")
# 执行对应的函数
if function_name == "get_curr_weather":
# 使用**function_args将字典解包为关键字参数
result = get_curr_weather(**function_args)
print(f"\n函数执行结果: {result}")
# 将函数执行结果发送回模型 - 完整的对话历史
messages = [
{"role": "user", "content": "深圳天气怎么样"} # 初始用户问题
]
# 添加助手的回复和工具调用 - 这是模型决定调用函数的回复
messages.append({
"role": "assistant",
"content": message.content,
"tool_calls": [{
"id": tool_call.id,
"type": "function",
"function": {
"name": function_name,
"arguments": tool_call.function.arguments
}
}]
})
# 添加工具的回复 - 这是函数执行后的结果
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
# 获取最终回复 - 模型根据函数结果生成的回复
try:
final_response = cli.chat.completions.create(
model="gpt-4o-mini",
messages=messages
)
print(f"\n最终回复: {final_response.choices[0].message.content}")
except Exception as e:
print(f"获取最终回复时出错: {str(e)}")
else:
print(f"未知的函数: {function_name}")
except json.JSONDecodeError as e:
print(f"解析函数参数时出错: {str(e)}")
print(f"原始参数字符串: {tool_call.function.arguments}")
else:
print("模型没有请求调用函数")
except Exception as e:
print(f"处理模型回复时出错: {str(e)}")
我们定义了一个 get_curr_weather 用于模拟获取天气信息,然后对第一次调用模型获取的结果进行解析获取到函数方法和参数,重新构造结果再喂给大模型获取最终的结果返回,执行后的输出如下:
函数调用请求: get_curr_weather
函数参数: {'location': '深圳'}
函数执行结果: 深圳的天气是25摄氏度
最终回复: 深圳的天气当前是25摄氏度,感觉宜人。请注意查看是否有其他天气变化,比如降雨或风速等信息。
我们可以通过定义多个方法和tools,来实现多工具协作。
当然,也可以使用 LangChain 实现,代码如下:
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
from langchain_core.tools import tool
@tool
def get_current_weather(location: str) -> str:
"""获取指定位置的当前天气信息。
Args:
location: 城市或地区名称
Returns:
包含天气信息的字符串
"""
return f"{location}的天气是25摄氏度"
llm = ChatOpenAI(
openai_api_key="sk-xxx",
base_url="https://vip.apiyi.com/v1",
model_name="gpt-4o-mini",
max_tokens=None,
timeout=None,
)
tools = [get_current_weather]
# 创建代理,设置最大迭代次数为3
agent = initialize_agent(
tools,
llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
response = agent.invoke({"input": "深圳的天气如何?"})
输出的结果是:
> Entering new AgentExecutor chain...
Thought: 我需要获取深圳的当前天气信息。
Action:
{
"action": "get_current_weather",
"action_input": "深圳"
}
Observation: 深圳的天气是25摄氏度
Thought:我现在知道深圳的当前天气是25摄氏度。
Final Answer: 深圳的天气是25摄氏度。
> Finished chain.
这样是不是可以和许多自动化工具结合起来做一些运维操作?比如 chatops 就更好实现了。
对于使用 Function Calling 有以下几点建议:
- 明确定义函数参数:使用 JSON Schema 描述参数类型、必填项、枚举值等
- 返回结构化结果:工具应返回结构化数据,便于模型理解和使用
- 异常处理机制:如果调用失败,应有重试、提示或替代方案
- 避免循环调用:控制最多调用次数,防止无限递归
- 支持多轮调用:有些任务可能需要多次调用不同工具才能完成
再次提醒:注意模型是否支持 Function Calling。
Fine-tuning
Fine-tuning(微调) 是指在预训练语言模型基础上,使用特定领域的数据对其进行进一步训练,以提升模型在该领域或任务上的表现。使用场景包括要求模型输出特定风格或格式、提高特定场景下的输出可靠性、纠正模型无法遵守复杂系统提示语的问题,以及执行难以用语言表达的新任务或技能。
下面以 日志分析专家 为例来说明。
1、准备原始的日志数据
log,优先级
[2024-08-07 12:00:00] Database connection failed. System is down.,P0
[2024-08-07 12:05:00] Unrecoverable error in payment processing module. System halted.,P0
[2024-08-07 12:10:00] Authentication service is not responding. All user access is blocked.,P0
[2024-08-07 12:15:00] Data corruption detected in primary storage. Immediate action required.,P0
[2024-08-07 13:15:00] System backup failed. Manual intervention needed.,P0
[2024-08-07 13:20:00] Disk I/O error. System is not booting up.,P0
2、对原始数据处理转换成json文件
import json
import csv
import os
def convert_csv_to_jsonl(csv_file_path,jsonl_file_path):
with open(csv_file_path, 'r', encoding='utf-8') as csv_file:
csv_reader = csv.DictReader(csv_file)
with open(jsonl_file_path, 'w', encoding='utf-8') as jsonl_file:
for row in csv_reader:
log = row['log']
priority = row['优先级']
json_entry = {
"messages": [
{
"role": "system",
"content": "你现在是一个日志告警专家,请根据日志内容去识别紧急程度,直接输出 P0 Pl 或者 P2,输出:"
},
{
"role": "user",
"content": log
},
{
"role": "assistant",
"content": priority
}
]
}
jsonl_file.write(json.dumps(json_entry, ensure_ascii=False) + '\n')
csv_file_path = os.path.join(os.path.dirname(__file__),"data","log.csv")
jsonl_file_path = os.path.join("log.jsonl")
convert_csv_to_jsonl(csv_file_path,jsonl_file_path)
转换后的日志文件如下:
{"messages": [{"role": "system", "content": "你现在是一个日志告警专家,请根据日志内容去识别紧急程度,直接输出 P0 P1 或者 P2,输出:"}, {"role": "user", "content": "[2024-08-07 12:00:00] Database connection failed. System is down."}, {"role": "assistant", "content": "P0"}]}
{"messages": [{"role": "system", "content": "你现在是一个日志告警专家,请根据日志内容去识别紧急程度,直接输出 P0 P1 或者 P2,输出:"}, {"role": "user", "content": "[2024-08-07 12:05:00] Unrecoverable error in payment processing module. System halted."}, {"role": "assistant", "content": "P0"}]}
{"messages": [{"role": "system", "content": "你现在是一个日志告警专家,请根据日志内容去识别紧急程度,直接输出 P0 P1 或者 P2,输出:"}, {"role": "user", "content": "[2024-08-07 12:10:00] Authentication service is not responding. All user access is blocked."}, {"role": "assistant", "content": "P0"}]}
{"messages": [{"role": "system", "content": "你现在是一个日志告警专家,请根据日志内容去识别紧急程度,直接输出 P0 P1 或者 P2,输出:"}, {"role": "user", "content": "[2024-08-07 12:15:00] Data corruption detected in primary storage. Immediate action required."}, {"role": "assistant", "content": "P0"}]}
{"messages": [{"role": "system", "content": "你现在是一个日志告警专家,请根据日志内容去识别紧急程度,直接输出 P0 P1 或者 P2,输出:"}, {"role": "user", "content": "[2024-08-07 13:15:00] System backup failed. Manual intervention needed."}, {"role": "assistant", "content": "P0"}]}
{"messages": [{"role": "system", "content": "你现在是一个日志告警专家,请根据日志内容去识别紧急程度,直接输出 P0 P1 或者 P2,输出:"}, {"role": "user", "content": "[2024-08-07 13:20:00] Disk I/O error. System is not booting up."}, {"role": "assistant", "content": "P0"}]}
3、现在对处理后的数据进行微调
我这里使用的 硅基流动 进行微调的,上传 jsonl 文件,选择对应模型即可获取到微调数据。
![[Pasted image 20250714104745.png]]
Tips:微调是异步的,当你上传微调数据后,需要等待其完成后才会获得微调模型。
当然,也可以使用代码:
from openai import OpenAI
client = OpenAI()
# 上传微调数据
file_name = client.files.create(
file=open("log.jsonl", "rb"),
purpose='fine-tune'
)
file_id = file_name.id
# 创建微调任务
fine_tune = client.fine_tuning.jobs.create(
training_file=file_id,
model="gpt-4o-mini-2024-07-18",
)
# 获取微调的 job_id
job_id = fine_tune.id
Tips:上面代码我没调通。
4、使用微调后的模型进行对话
现在我们使用微调后的模型进行对话:
from openai import OpenAI
client = OpenAI(
api_key="sk-xxxxx",
base_url="https://api.siliconflow.cn/v1",
)
mode_id = "ft:LoRA/Qwen/Qwen2.5-7B-Instruct:34xdk93rgd:log:zxtxltvubdatuwgclxyr"
completion = client.chat.completions.create(
model=mode_id,
messages=[
{"role": "system", "content": "你现在是一个日志告警专家,请根据日志内容去识别紧急程度,直接输出 P0 Pl 或者 P2,输出:"},
{
"role":"user",
"content": "Disk I/O error"
}
]
)
print(completion.choices[0].message.content)
执行程序后输出的内容如下:
> python .\03chat.py
P0
微调过程在不同的商用模型或开源模型中基本相似,主要依赖于一致的数据格式,如JCL,用于训练模型以优化其性能。微调最重要的环节是微调数据的来源,需要大量的高质量人工标注数据,以帮助模型学习和理解数据中的逻辑关系。
检索增强生成(RAG、Graph RAG)
RAG
RAG(Retrieval-Augmented Generation) 是一种结合 信息检索(Retrieval) 和 语言生成(Generation) 的 AI 架构,用于在回答问题或生成文本时动态地从外部知识库中检索相关信息,并将其作为上下文提供给大语言模型(LLM),从而提高输出的准确性和相关性。
简单来说就是:先查资料,再写答案。
其步骤主要包含以下2步:
- 索引——对私有知识库建立索引,包含加载知识库、拆分、向量化和存储。
- 检索和生成——从私有知识库中查询有关信息,并传递给模型进行对话。
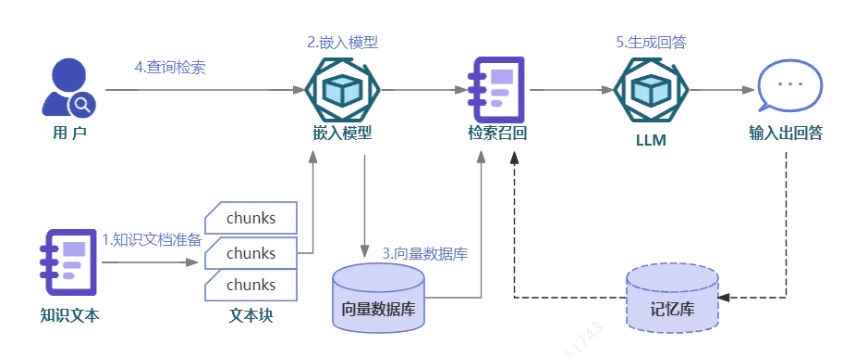
索引
在 索引 部分就是对私有知识库建立索引,主要包含:
- 加载:通过文档加载器将不同格式的文档,如text、word、excel、PPT、PDF等,进行文本化处理。
- 拆分:由于大模型的上下文长度限制,需要将文档按段落或其他策略(如按特殊分隔符、标题等)进行拆分。
- 向量化处理:对拆分后的文档片段进行向量化处理。
- 向量化存储:将向量化后的文档片段存储在向量数据库中,完成索引阶段。
检索和生成
检索和生成 分为两步:
- 检索:根据用户的输入,借助检索器从向量数据库中检索出相关的块。
- 生成:LLM 使用包含问题答案的块进行回答。
示例
下面我们以一个简单的例子。
1、准备私有知识库
这里准备一个简单的 markdown 知识库,如下:
# 支付系统运维知识库
## 1. 系统监控指标
- **交易量**: 监控每秒交易数,确保系统承载能力。
- **响应时间**: 监控交易的平均响应时间,确保服务性能。
- **系统负载**: 监控CPU、内存等资源使用率,避免资源瓶颈。
## 2. 常见问题与解决方案
### 2.1 交易失败
- **问题描述**: 用户发起支付后,交易未能成功完成。
- **可能原因**:
- 网络延迟或中断
- 支付网关服务异常
- **解决办法**:
- 检查网络连接,确保支付服务的网络畅通。
- 检查支付网关服务状态,重启服务或联系服务提供商。
### 2.2 响应时间过长
- **问题描述**: 用户支付请求处理时间超过正常范围。
- **可能原因**:
- 系统资源不足
- 数据库查询效率低下
- 外部服务响应慢
- **解决办法**:
- 增加系统资源,如CPU、内存。
- 优化数据库查询,使用索引,减少复杂查询。
- 与外部服务提供商沟通,优化接口性能。
### 2.3 系统宕机
- **问题描述**: 支付系统完全无法访问或服务中断。
- **可能原因**:
- 主机硬件故障
- 系统软件崩溃
- 网络设备故障
- **解决办法**:
- 快速切换到备用服务器。
- 检查系统日志,定位问题原因。
- 联系硬件供应商,进行故障排查和修复。
### 2.4 安全问题
- **问题描述**: 检测到异常交易或系统遭受攻击。
- **可能原因**:
- 账户被盗用
- 系统存在安全漏洞
- DDoS攻击
- **解决办法**:
- 立即冻结异常账户,通知用户。
- 检查系统安全设置,更新安全补丁。
- 启用DDoS防护措施,如流量清洗。
## 3. 日常运维任务
- **数据备份**: 定期备份数据库和重要文件,确保数据安全。
- **系统更新**: 定期更新系统和软件,修复已知漏洞。
- **性能调优**: 定期检查系统性能,进行必要的优化。
## 4. 应急响应流程
- **发现问题**: 监控系统发现异常指标。
- **快速响应**: 立即通知运维团队,进行初步诊断。
- **问题定位**: 通过日志分析,定位问题原因。
- **解决方案**: 根据问题类型,执行相应的解决方案。
- **问题解决**: 确认问题解决,恢复正常服务。
- **后续跟进**: 记录问题处理过程,进行事后分析和总结。
## 5. 性能优化建议
- **代码优化**: 定期审查代码,优化算法和逻辑。
- **资源扩展**: 根据业务增长,适时扩展系统资源。
- **负载均衡**: 使用负载均衡技术,分散请求压力。
## 6. 安全策略
- **访问控制**: 严格控制系统访问权限,实行最小权限原则。
- **数据加密**: 对敏感数据进行加密处理,保护用户隐私。
- **安全审计**: 定期进行安全审计,检查潜在的安全风险。
## 7. 联系方式
- **技术支持**: support@example.com
- **紧急联系**: emergency@example.com
- **客服热线**: 123-456-7890
## 8. 业务负责人
- **payment**: 小张,联系方式:18888888888
- **payment_gateway**: 小王,联系方式:18888888889
- **payment_callback**: 小李,联系方式:18888888890
2、开发代码
(1)、安装依赖包
pip install -qU langchain-openai langchain langchain_community langchainhub chromadb==0.5.3
其中 chromadb 是向量数据库,这里使用它来本地存储向量化后的数据。
(2)、开发代码
首先,将知识库进行向量化存储,代码如下:
from langchain import hub as langchain_hub
from langchain.schema import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.text_splitter import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
import os
from langchain_community.vectorstores.chroma import Chroma
# 读取./data/data.md 文件作为运维知识库
file_path = os.path.join(os.path.dirname(__file__),"data", "data.md")
with open(file_path, "r", encoding="utf-8") as f:
docs_text = f.read()
# 对文档进行分块,这里使用Markdown标题格式进行分块
headers_split = [
("#", "标题"),
("##", "二级标题"),
("###", "三级标题"),
]
# 初始化文本分块器
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_split)
splits = text_splitter.split_text(docs_text)
# 将知识库的每一块文本向量化,然后存储到向量数据库中
embeddings = OpenAIEmbeddings(
openai_api_key="sk-u14n5jF9bdZOKWQ47dD365F221144a31B367A637E4Ac4851",
openai_api_base="https://vip.apiyi.com/v1",
model="text-embedding-3-small",
)
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory=os.path.join(os.path.dirname(__file__), "chroma_db"),
)
vectorstore.persist()
这里会将数据向量化存储到本地当前目前 chroma_db 中。
对于 RAG 的向量检索,会将所有分片进行向量化处理,然后计算输入问题与这些文本向量之间的相似度,找出最相近的向量,一般采用 余弦相似度 和 欧几里得距离,其中余弦相似度值越小表示越相似。

下面介绍两种不同的方法查看向量搜索的相似度。
similarity_search_with_scoresimilarity_search_by_vector_with_relevance_scores
它们都属于 向量数据库(Vector Store) 提供的功能,用于在 RAG 系统中进行相似性检索。虽然它们看起来功能相似,但使用场景和输入方式略有不同 。
首先使用 similarity_search_with_score 方法:
# 进行文本相似性检索
results = vectorstore.similarity_search_with_score(
"payment 服务",
key=1
)
for res,score in results:
print(f"[相似性={score:3f}] {res.page_content} [{res.metadata}]")
可以看到输出的内容为:
[相似性=0.877636] - **payment**: 小张,联系方式:18888888888
- **payment_gateway**: 小王,联系方式:18888888889
- **payment_callback**: 小李,联系方式:18888888890 [{'二级标题': '8. 业务负责人', '标题': '支付系统运维知识库'}]
然后使用 similarity_search_by_vector_with_relevance_scores 再通过向量检索:
# 向量检索
results = vectorstore.similarity_search_by_vector_with_relevance_scores(
embedding=embeddings.embed_query("payment 服务是谁维护的?"),
key=1
)
for doc,score in results:
print(f"[相似性={score:3f}] {doc.page_content} [{doc.metadata}]")
其输出为:
[相似性=1.074331] - **payment**: 小张,联系方式:18888888888
- **payment_gateway**: 小王,联系方式:18888888889
- **payment_callback**: 小李,联系方式:18888888890 [{'二级标题': '8. 业务负责人', '标题': '支付系统运维知识库'}]
虽然搜索出的内容是一致的,但是通过 向量检索 的相似度更高。
在使用OpenAI的embedding模型进行向量化处理的时候,会对每个分片进行向量化,然后返回特定维度的向量:
# 查看向量检索的向量
from openai import OpenAI
client = OpenAI(
base_url="https://vip.apiyi.com/v1",
api_key="sk-u14n5jF9bdZOKWQ47dD365F221144a31B367A637E4Ac4851",
)
response = client.embeddings.create(
model="text-embedding-3-small",
input="payment 服务是谁维护的?",
)
print(response.data[0].embedding)
其输出为一组向量值:

这里使用的 text-embedding-3-small 模型,它还支持 text-embedding-3-large 和 text-embedding-ada-002 模型,不同的模型的价格和向量维度不一样。
最后,我们写一个 Chat 来进行运维知识库的问答,代码如下:
# 使用运维知识库进行检索生成
# 1.创建检索器
retriever = vectorstore.as_retriever()
# 2.导入prompt
prompt = langchain_hub.pull('rlm/rag-prompt')
# 3.创建llm
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
llm = ChatOpenAI(
base_url="https://vip.apiyi.com/v1",
api_key="sk-xxx",
model="gpt-4o-mini"
)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 4. 测试问答
res = rag_chain.invoke("payment 服务是谁维护的?")
print(res)
其输出是我们希望的结果,如下:
支付服务由小张维护,联系方式是18888888888。
这个过程说明,通过 RAG 处理后,系统能够精确地从数据中抽取所需信息,最终GPT能够基于此提供准确的回答。
不过,RAG 也有一些缺点,如下:
- 由于文本分片会把上下文逻辑截断,可能导致无法回答内在逻辑关联的问题
- 只能问答显式检索问题,无法回答全局性/总结性问题,例如:"谁维护的服务最多?"
这时候,我们可以考虑使用 Graph RAG 来解决传统 RAG 无法理解文档对象及其内在逻辑问题。
Graph RAG
Graph RAG(Graph-based Retrieval-Augmented Generation) 是一种将 知识图谱(Knowledge Graph) 与 RAG(Retrieval-Augmented Generation) 相结合的方法。它利用图结构来组织和检索信息,使得模型在回答复杂问题时能够更高效地获取相关上下文,并进行更深层次的推理。
Graph RAG 的核心思想是:
- 构建知识图谱
- 将文档内容解析为实体(Entity)和关系(Relation)
- 构建节点-边结构的图数据库(如 Neo4j、Amazon Neptune)
- 图驱动检索(Graph-Aware Retrieval)
- 用户输入查询后,系统不仅查找语义相似的文档片段
- 还会通过图结构挖掘相关实体及其连接路径
- 图+文本混合生成(Graph + Text Generation)
- LLM 同时使用原始文本和图结构中的相关信息生成答案
通过在知识图谱中进行查询,Graph RAG有效克服了传统RAG在技术上存在的两大缺陷,即无法理解实体间关系和文档内对象的内部逻辑。
1、开发代码
(1)、安装依赖包
pip install graphrag
(2)、初始化工作区
python init --root ./data
(3)设置必要的环境变量
编辑 .env 文件,设置以下环境变量:
GRAPHRAG_API_KEY=sk-xxx
GRAPHRAG_API_BASE=
修改 settings.yaml 文件的 models 参数
models:
default_chat_model:
type: openai_chat
api_base: ${GRAPHRAG_API_BASE}
api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file
model: gpt-4o-mini
...
default_embedding_model:
type: openai_embedding
api_base: ${GRAPHRAG_API_BASE}
api_key: ${GRAPHRAG_API_KEY}
model: text-embedding-3-small
...
(4)将文档放入 input 目录下,注意文件类型:csv, text, json
(5)建立索引
graphrag index --root ./data
其输出如下:
[1 rows x 15 columns]
⠹ GraphRAG Indexer
├── Loading Input (InputFileType.text) - 1 files loaded (0 filtered) ━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00├── create_base_text_units ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
⠼ GraphRAG Indexer
├── Loading Input (InputFileType.text) - 1 files loaded (0 filtered) ━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00├── create_base_text_units ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
⠸ GraphRAG Indexer
├── Loading Input (InputFileType.text) - 1 files loaded (0 filtered) ━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00├── create_base_text_units ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
🚀 generate_text_embeddings
{'entity.description': id
embedding
0 66a3e82b-c9cf-48f7-b722-e26bc78bacfc [-0.017157575115561485, -0.03000674955546856, ...
1 bacfb1fb-ae38-4f18-b49a-bcd58d513e6f [-0.006344724912196398, -0.02774975262582302, ...
2 95101427-e65b-4809-8355-5aafeadd8153 [-0.012414857745170593, -0.03073010966181755, ...
3 25ec9415-4abd-4c2b-accb-0f95c6dbb17b [0.005169904325157404, -0.030199555680155754, ...
4 7117fa3b-0daa-4dcc-ae75-c17e55207d3d [-0.023918526247143745, -0.038444504141807556,...
5 4085c873-3848-4834-b029-81f913c78ced [-0.0224880613386631, -0.02436511404812336, 0....
6 7330370c-cc4e-4d75-be00-5a4c5c906350 [-0.003509489120915532, -0.038598403334617615,...,
'community.full_content': id
embedding
0 ec30abcec7814ae8bf45f9b65c63cf63 [-0.0028976777102798223, 0.0026051404420286417..., 'text_unit.text':id embedding
0 cd289493e1ec671d497ef05ba1bcaf4e2c9bee94f52bce... [-0.007051201071590185, 0.017086070030927658, ...
1 df11f14d0d76a99698ea3d4d6774a6716065760b8ffad3... [0.0032748274970799685, -0.017688022926449776,...}
⠼ GraphRAG Indexer
├── Loading Input (InputFileType.text) - 1 files loaded (0 filtered) ━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00├── create_base_text_units ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_final_documents ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── extract_graph ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── finalize_graph ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_communities ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_final_text_units ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_community_reports ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── generate_text_embeddings ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
🚀 All workflows completed successfully.
(6)、进行查询
使用 cli 命令进行查询:
graphrag query --root ./data --method basic -q "谁负责的业务最多?"
其输出如下:
INFO: Vector Store Args: {
"default_vector_store": {
"type": "lancedb",
"url": null,
"audience": null,
"container_name": "==== REDACTED ====",
"database_name": null,
"overwrite": true
}
}
SUCCESS: Basic Search Response:
根据提供的数据,业务负责人中,小张负责的业务最多。具体来说,小张负责了支付系统的后端(payment_backend)和
前端(payment_frontend),这两个角色的联系方式均为18888888888 [Data: Sources (1, 0)]。此外,小王负责支付
网关(payment_gateway),联系方式为18888888889,而小李负责支付回调(payment_callback),联系方式为18888888890 [Data: Sources (1, 0)]。
因此,小张在业务负责人中承担了最多的责任,负责了两个主要的支付系统业务。
可以看到,Graph RAG 相较于传统 RAG 工具,能处理更广泛的场景,尤其在总结性和分析性问题上表现更佳,提供更全面的数据分析能力。
(7)借助 Neo4j 查看实体关系
首先使用 Docker 安装 Neo4j,命令如下:
docker run -it \
--name neo4j-apoc \
-p 7474:7474 \
-p 7687:7687 \
-e NEO4J_APOC_EXPORT_FILE_ENABLED=true \
-e NEO4J_APOC_IMPORT_FILE_ENABLED=true \
-e NEO4J_APOC_IMPORT_FILE_USE_NEO4J_CONFIG=true \
-e NEO4J_PLUGINS='["apoc"]' \
docker.1ms.run/neo4j:5.21.2
启动成功后使用 http://ip:7474 登录,第一次登录使用默认账号密码 neo4j:neo4j 进行登录,然后会修改密码。
然后安装依赖:
pip install --quiet pandas neo4j-rust-ext
核心代码如下:
import pandas as pd
from neo4j import GraphDatabase
import time
import os
# 使用绝对路径
GRAPHRAG_FOLDER=os.path.join(os.path.dirname(os.path.abspath(__file__)), "data", "output")
NEO4J_URL="neo4j://127.0.0.1:7687"
NEO4J_USER="neo4j"
NEO4J_PASSWORD="miguel-wave-tribune-engine-fragile-3408"
NEO4J_DATABASE="neo4j"
# 创建 NEO4J 数据库连接
driver = GraphDatabase.driver(NEO4J_URL, auth=(NEO4J_USER, NEO4J_PASSWORD))
statements = """
create constraint chunk_id if not exists for (c:__Chunk__) require c.id is unique;
create constraint document_id if not exists for (d:__Document__) require d.id is unique;
create constraint entity_id if not exists for (c:__Community__) require c.community is unique;
create constraint entity_id if not exists for (e:__Entity__) require e.id is unique;
create constraint entity_title if not exists for (e:__Entity__) require e.name is unique;
create constraint entity_title if not exists for (e:__Covariate__) require e.title is unique;
create constraint related_id if not exists for ()-[rel:RELATED]->() require rel.id is unique;
""".split(";")
for statement in statements:
if len((statement or "").strip()) > 0:
print(statement)
driver.execute_query(statement)
def batched_import(statement, df, batch_size=1000):
"""
Import a dataframe into Neo4j using a batched approach.
Parameters: statement is the Cypher query to execute, df is the dataframe to import, and batch_size is the number of rows to import in each batch.
"""
total = len(df)
start_s = time.time()
for start in range(0,total, batch_size):
batch = df.iloc[start: min(start+batch_size,total)]
result = driver.execute_query("UNWIND $rows AS value " + statement,
rows=batch.to_dict('records'),
database_=NEO4J_DATABASE)
print(result.summary.counters)
print(f'{total} rows in { time.time() - start_s} s.')
return total
doc_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/documents.parquet', columns=["id", "title"])
doc_df.head(2)
# import documents
statement = """
MERGE (d:__Document__ {id:value.id})
SET d += value {.title}
"""
batched_import(statement, doc_df)
text_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/text_units.parquet',
columns=["id","text","n_tokens","document_ids"])
text_df.head(2)
statement = """
MERGE (c:__Chunk__ {id:value.id})
SET c += value {.text, .n_tokens}
WITH c, value
UNWIND value.document_ids AS document
MATCH (d:__Document__ {id:document})
MERGE (c)-[:PART_OF]->(d)
"""
batched_import(statement, text_df)
entity_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/entities.parquet',
columns=["title", "type", "description", "human_readable_id", "id", "text_unit_ids"])
entity_df.head(2)
entity_statement = """
MERGE (e:__Entity__ {id:value.id})
SET e += value {.human_readable_id, .description, name:replace(value.title,'"','')}
WITH e, value
CALL apoc.create.addLabels(e, case when coalesce(value.type,"") = "" then [] else [apoc.text.upperCamelCase(replace(value.type,'"',''))] end) yield node
UNWIND value.text_unit_ids AS text_unit
MATCH (c:__Chunk__ {id:text_unit})
MERGE (c)-[:HAS_ENTITY]->(e)
"""
batched_import(entity_statement, entity_df)
rel_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/relationships.parquet',
columns=["source", "target", "id", "weight", "human_readable_id", "description",
"text_unit_ids"])
rel_df.head(2)
rel_statement = """
MATCH (source:__Entity__ {name:replace(value.source,'"','')})
MATCH (target:__Entity__ {name:replace(value.target,'"','')})
// not necessary to merge on id as there is only one relationship per pair
MERGE (source)-[rel:RELATED {id: value.id}]->(target)
SET rel += value {.weight, .human_readable_id, .description, .text_unit_ids}
RETURN count(*) as createdRels
"""
batched_import(rel_statement, rel_df)
community_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/communities.parquet',
columns=["community", "level", "title", "text_unit_ids", "relationship_ids"])
community_df.head(2)
statement = """
MERGE (c:__Community__ {community:value.community})
SET c += value {.level, .title}
/*
UNWIND value.text_unit_ids as text_unit_id
MATCH (t:__Chunk__ {id:text_unit_id})
MERGE (c)-[:HAS_CHUNK]->(t)
WITH distinct c, value
*/
WITH *
UNWIND value.relationship_ids as rel_id
MATCH (start:__Entity__)-[:RELATED {id:rel_id}]->(end:__Entity__)
MERGE (start)-[:IN_COMMUNITY]->(c)
MERGE (end)-[:IN_COMMUNITY]->(c)
RETURn count(distinct c) as createdCommunities
"""
batched_import(statement, community_df)
community_report_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/community_reports.parquet',
columns=["id", "community", "level", "title", "summary", "findings", "rank",
"rating_explanation", "full_content"])
community_report_df.head(2)
# import communities
community_statement = """MATCH (c:__Community__ {community: value.community})
SET c += value {.level, .title, .rank, .rating_explanation, .full_content, .summary}
WITH c, value
UNWIND range(0, size(value.findings)-1) AS finding_idx
WITH c, value, finding_idx, value.findings[finding_idx] as finding
MERGE (c)-[:HAS_FINDING]->(f:Finding {id: finding_idx})
SET f += finding"""
batched_import(community_statement, community_report_df)
其输出如下:
create constraint chunk_id if not exists for (c:__Chunk__) require c.id is unique
create constraint document_id if not exists for (d:__Document__) require d.id is unique
create constraint entity_id if not exists for (c:__Community__) require c.community is unique
create constraint entity_id if not exists for (e:__Entity__) require e.id is unique
create constraint entity_title if not exists for (e:__Entity__) require e.name is unique
create constraint entity_title if not exists for (e:__Covariate__) require e.title is unique
create constraint related_id if not exists for ()-[rel:RELATED]->() require rel.id is unique
{'_contains_updates': True, 'properties_set': 1}
1 rows in 0.011118888854980469 s.
{'_contains_updates': True, 'properties_set': 4}
2 rows in 0.012151956558227539 s.
{'_contains_updates': True, 'properties_set': 21}
7 rows in 0.14493465423583984 s.
{'_contains_updates': True, 'properties_set': 20}
5 rows in 0.10936474800109863 s.
{'_contains_updates': True, 'properties_set': 2}
1 rows in 0.13402175903320312 s.
{'_contains_updates': True, 'properties_set': 12}
1 rows in 0.11609745025634766 s.
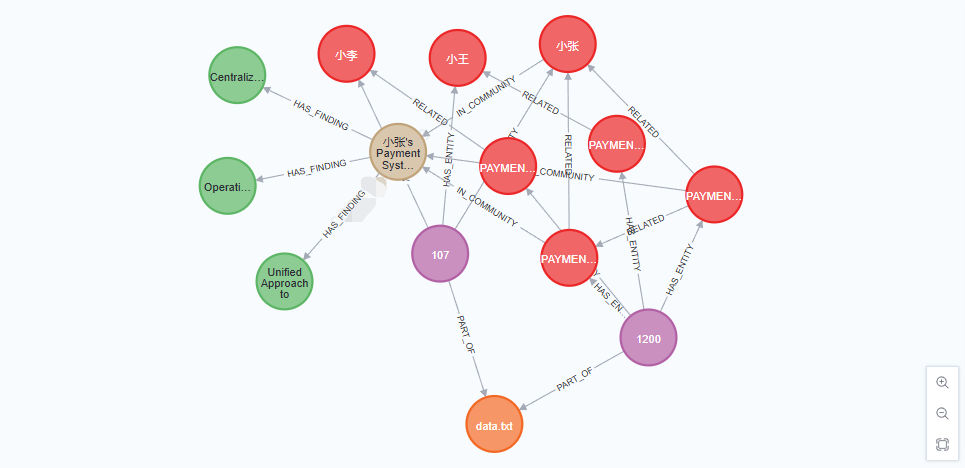
进入 NEO4J 控制面板,输入 MATCH (a)-[r]->(b) RETURN a, r, b LIMIT 20 可以查看关联图,如下:
初次之外,还可以使用一些开源工具来做,比如 **RAGFlow
本地部署常见的开源模型并推理
运维相关的知识文档以及AI操作对数据的敏感度比较高,使用外部的大模型可能产生数据泄露风险,在条件允许的情况下最好在本地部署开源模型。
目前,本地部署大模型的工具链比较多,比如:
- Ollama
- LM Studio
- FastChat
- ...
这里使用 Ollama 工具做简单介绍。
(1)、安装 Ollama
# macOS / Linux 用户可直接运行:
curl -fsSL https://ollama.com/install.sh | sh
(2)、本地启动大模型
ollama run llama3.1
支持的部分模型如下:
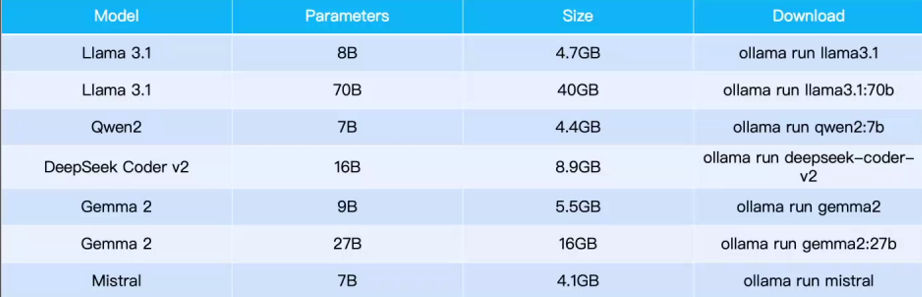
(3)、定制 System Prompt
在使用 Ollama 时,你可能会希望自定义模型的 System Prompt(系统提示) ,以控制模型的行为风格、角色设定或任务目标。
首先,拉取模型:
ollama pull llama3.1
然后,新增 Modefile 文件,内容如下:
FROM llama3.1
SYSTEM """You are an AI assistant specialized in DevOps and system administration. Always provide concise, accurate, and actionable advice."""
然后,创建模型:
ollama create mario -f ./Modefile
最后,运行模型:
ollama run mario
(4)使用 API 访问 Ollama 部署的大模型
Ollama 部署的大模型兼容 OpenAI 的接口,如下:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.1",
"messages": [{"role": "user", "content": "你好,请介绍你自己"}]
}'
(5)部署 Open WebUI 为模型提供 Web 界面
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
然后使用 http://ip:3000 进行访问。
Tips:Open WebUI的使用比较简单,不再赘述。
总结
本文围绕 AIOps 智能运维 与 大语言模型(LLM) 的结合展开,介绍了 Prompt Engineering、Function Calling、RAG、Graph RAG、本地模型部署等关键技术的应用方式,并通过实际示例展示了如何将这些技术用于日志分析、故障定位、智能问答和自动化运维场景。
我们看到,Prompt 是引导模型输出的核心工具 ,而 Function Calling 和 Memory 机制 则让模型具备了“执行能力”和“记忆能力”。RAG 和 Graph RAG 的引入,使得系统能够在不微调模型的前提下,灵活接入企业知识库,提升回答的准确性与逻辑性。
此外,为保障数据安全、降低使用成本,本地部署开源模型 成为越来越多企业的选择。Ollama、FastChat、Text Generation WebUI 等工具,使得本地推理变得简单高效。