



随着微服务以及云原生的发展,越来越多的企业都将业务部署运行到Kubernetes中,主要是想依托Kubernetes的可扩展、可伸缩、自动化以及高稳定性来保障业务的稳定性。
然而,Kubernetes本身是一个复杂的管理系统,它既然是作为企业业务的基础设施,其本身以及运行在集群内部的业务系统对于企业来说都变得非常重要。为此,在实际工作中,我们会借助需要得监控手段来提升Kubernetes本身以及业务的可观测性,常见的有:
- 使用cAdvisor来获取容器的资源指标,比如cpu、内存;
- 使用kube-state-metrics来获取资源对象的状态指标,比如Deployment、Pod的状态;
- 使用metrics-server来获取集群范围内的资源数据指标;
- 使用node-exporter等一系列官方以及非官方的exporter来获取特定组件的指标;
在大部分的监控场景中,我们都是对特定资源进行特定监控,比如Pod,Node等。但是,在Kubernetes中还有一些场景是无法通过资源来表述的,就是说它们不是特定的资源,比如Pod调度、重启,在Kubernetes中,这类场景主要称之为事件。
在Kubernetes中,存在两种事件:
- Warning事件,事件的状态转换是在非预期的状态之间产生。
- Normal事件,期望达到的状态和目前的状态是一致的。
在这里,我们用Pod来进行说明。当创建Pod的时候,会先进入Pending状态,然后在进入Creating状态(主要是在拉取镜像),再进去NotReady状态(主要是应用启动并且等待健康检测通过),最后进入Running状态,这整个过程就会生成Normal事件。但是,如果在运行过程中,如果Pod因为一些异常原因进入其他状态,比如节点驱逐、OOM等,在这个状态转换的过程中,就会产生Warning事件。在Kubernetes中,我们可以通过其他办法来保障业务的稳定性,比如为了避免Pod调度到一个节点或者同可用区等而采用亲和性以及反亲和性调度,为了避免节点驱逐导致某个单个Pod不可用而采用的PDB等,也许某个Warning事件并不会对整个业务的稳定性带来致命的影响,但是如果能够通过监控事件的手段来感知集群的某个状态变化是有助于进行查漏补缺的,也有助于我们感知一些容易忽略的问题。
在Kubernetes中,所有事件都通过事件系统记录到APIServer中,并且最终存入在Etcd中,我们可以通过API或者kubectl进行查看,比如:

也可以查看某个对象的事件,比如:

事件包含了时间、类型、对象、原因以及描述等,通过事件我们能够知道应用的部署、调度、运行、停止等整个生命周期,也能通过事件去了解系统中正在发生的一些异常。在Kubernetes各个组件的源码中都会定义该组件可能会触发的事件类型,比如在kubelet的源码中定义了许多的事件类型,如下:
package events
// Container event reason list
const (
CreatedContainer = "Created"
StartedContainer = "Started"
FailedToCreateContainer = "Failed"
FailedToStartContainer = "Failed"
KillingContainer = "Killing"
PreemptContainer = "Preempting"
BackOffStartContainer = "BackOff"
ExceededGracePeriod = "ExceededGracePeriod"
)
// Pod event reason list
const (
FailedToKillPod = "FailedKillPod"
FailedToCreatePodContainer = "FailedCreatePodContainer"
FailedToMakePodDataDirectories = "Failed"
NetworkNotReady = "NetworkNotReady"
)
......
Kubernetes事件最终是存在Etcd中,默认只保存1小时,由于Etcd本身并不支持一些复杂的分析操作,只能被动的存在Etcd中,并不支持主动推送到其他系统,通常情况下只能手动去查看。
在实际中,我们对Kubernetes事件还有其他的需求,比如:
- 希望对异常的事件做告警处理;
- 希望查询更长事件的历史事件;
- 希望对集群事件进行灵活的统计分析;
为此,我们需要单独对Kubernetes事件进行收集,以便适用于查询以及告警。
在社区中,有很多工具来做事件的收集以及告警,我常用的两个工具是:
- kube-eventer:阿里云推出的事件收集工具;
- kube-event-exporter:Github上另外一个事件收集工作;
在实际工作中,可以选择使用其中一个,基本都能满足收集以及告警功能。在这里,我将同时使用上面两个插件,用kube-eventer来进行告警,用kube-event-exporter将事件收集到ES中进行查看和分析。
使用kube-eventer进行事件告警
kube-eventer的告警通道可以企业微信、钉钉以及webhook。可以根据需要进行选择,每个组件的具体使用方法在项目的docs/en目录中,这里选择使用webhook将告警发送到企业微信中。
(1)首先需要在企业微信群里创建一个webhook机器人,然后获取webhook地址。
(2)在Kubernetes集群中部署kube-eventer。
# cat kube-eventer.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: kube-eventer
name: kube-eventer
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: kube-eventer
template:
metadata:
labels:
app: kube-eventer
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
dnsPolicy: ClusterFirstWithHostNet
serviceAccount: kube-eventer
containers:
- image: registry.aliyuncs.com/acs/kube-eventer:v1.2.7-ca03be0-aliyun
name: kube-eventer
command:
- "/kube-eventer"
- "--source=kubernetes:https://kubernetes.default.svc.cluster.local"
## .e.g,dingtalk sink demo
#- --sink=dingtalk:[your_webhook_url]&label=[your_cluster_id]&level=[Normal or Warning(default)]
#- --sink=webhook:https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=07055f32-a04e-4ad7-9cb1-d22352769e1c&level=Warning&label=oa-k8s
- --sink=webhook:http://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=888888-888-8888-8888-d35c52ff2e0b&level=Warning&header=Content-Type=application/json&custom_body_configmap=custom-webhook-body&custom_body_configmap_namespace=monitoring&method=POST
env:
# If TZ is assigned, set the TZ value as the time zone
- name: TZ
value: "Asia/Shanghai"
volumeMounts:
- name: localtime
mountPath: /etc/localtime
readOnly: true
- name: zoneinfo
mountPath: /usr/share/zoneinfo
readOnly: true
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 250Mi
volumes:
- name: localtime
hostPath:
path: /etc/localtime
- name: zoneinfo
hostPath:
path: /usr/share/zoneinfo
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-eventer
rules:
- apiGroups:
- ""
resources:
- events
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-eventer
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-eventer
subjects:
- kind: ServiceAccount
name: kube-eventer
namespace: monitoring
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-eventer
namespace: monitoring
---
apiVersion: v1
data:
content: >-
{"msgtype": "text","text": {"content": "集群事件告警\n事件级别: {{ .Type }}\n名称空间: {{ .InvolvedObject.Namespace }}\n事件类型: {{ .InvolvedObject.Kind }}\n事件对象: {{ .InvolvedObject.Name }}\n事件原因: {{ .Reason }}\n发生时间: {{ .LastTimestamp }}\n详细信息: {{ .Message }}"}}
kind: ConfigMap
metadata:
name: custom-webhook-body
namespace: monitoring
在webhook的配置中增加了level=Warning,表示只要Warning事件才会告警通知,除此之外,还可以通过namespaces字段来过来需要告警的命名空间,同kinds字段来过滤需要告警的对象,比如只需要发送Node的Warning事件,则可以写成level=warning&kinds=Node。再比如,如果不想产生非常多的告警风暴,只发送某些特定原因的告警,比如系统OOM的事件,可以增加reason=SystemOOM等待。
当kube-eventer的Pod启动完成后,企业微信即可收到满足条件的事件告警,比如:
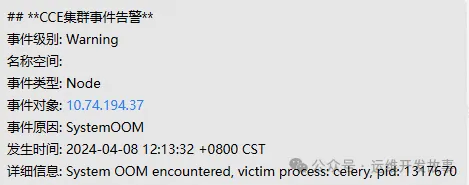
默认的kube-eventer没有太多节点问题事件,比如磁盘不可写,内存错误,内核错误等等,这时候需要结合node-problem-detector来进行监控。改组件也是将节点问题以事件的形式推送给APIServer,用户可以通过kubectl get event来进行查看。
这里可以采用Helm来进行部署,步骤如下:
helm repo add deliveryhero https://charts.deliveryhero.io/
helm install --generate-name deliveryhero/node-problem-detector -n monitoring
部署完成后,如果节点有异常事件,也会通过上面的webhook推送到企业微信。
另外,node-problem-detector也支持将事件以prometheus的格式输出,我们可以对其进行采集,只需要修改helm chart的values.yaml,修改部分如下:
metrics:
# metrics.enabled -- Expose metrics in Prometheus format with default configuration.
enabled: true
然后使用helm upgrade更新即可。当使用Prometheus收集完指标,可以导入Grafana面板,可以查看事件的一些统计指标,如下:
使用kube-event-exporter收集集群事件
上面使用kube-eventer进行事件告警,本质上并没有存储历史事件,而实际中可能需要查询历史事件并且对其做一些事件分析,而ES是常用于进行内容收集并通过kibana进行查看和分析,所以这里我们将使用kube-event-exporter收集Kubernetes事件到ES中。
kube-event-exporter可以直接将事件存入ES,也可以将事件发送到kafka,然后再通过Logstash消费Kafka中的数据将其存入ES。在这里,我基于环境现状,将事件发送给Kafka,然后再消费收集到ES。
(1)部署kube-event-exporter
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: monitoring
name: event-exporter
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: event-exporter
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: view
subjects:
- kind: ServiceAccount
namespace: monitoring
name: event-exporter
---
apiVersion: v1
kind: ConfigMap
metadata:
name: event-exporter-cfg
namespace: monitoring
data:
config.yaml: |
logLevel: error
logFormat: json
route:
routes:
- match:
- receiver: "kafka"
drop:
- kind: "Service"
receivers:
- name: "kafka"
kafka:
clientId: "kubernetes"
topic: "kubenetes-event"
brokers:
- "192.168.100.50:9092"
- "192.168.100.51:9092"
- "192.168.100.52:9092"
compressionCodec: "snappy"
layout: #optional
kind: "{{ .InvolvedObject.Kind }}"
namespace: "{{ .InvolvedObject.Namespace }}"
name: "{{ .InvolvedObject.Name }}"
reason: "{{ .Reason }}"
message: "{{ .Message }}"
type: "{{ .Type }}"
timestamp: "{{ .GetTimestampISO8601 }}"
cluster: "sda-pre-center"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: event-exporter
namespace: monitoring
spec:
replicas: 1
template:
metadata:
labels:
app: event-exporter
version: v1
spec:
serviceAccountName: event-exporter
containers:
- name: event-exporter
image: ghcr.io/resmoio/kubernetes-event-exporter:latest
imagePullPolicy: IfNotPresent
args:
- -conf=/data/config.yaml
volumeMounts:
- mountPath: /data
name: cfg
volumes:
- name: cfg
configMap:
name: event-exporter-cfg
selector:
matchLabels:
app: event-exporter
version: v1
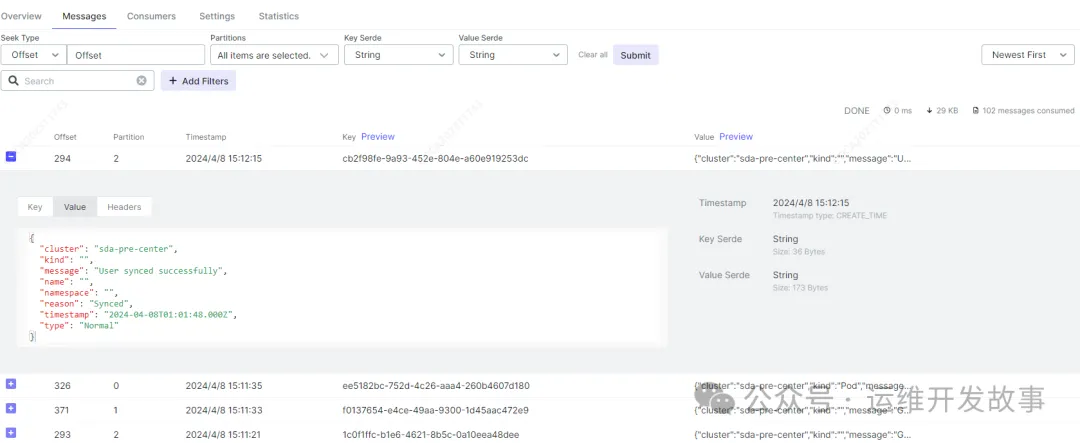
当kube-event-exporter的Pod启动过后,可以在kafka中查看到收集的事件,如下:
(2)部署logstash将事件存入ES
kind: Deployment
apiVersion: apps/v1
metadata:
name: kube-event-logstash
namespace: log
labels:
app: kube-event-logstash
spec:
replicas: 1
selector:
matchLabels:
app: kube-event-logstash
template:
metadata:
creationTimestamp: null
labels:
app: kube-event-logstash
annotations:
kubesphere.io/restartedAt: '2024-02-22T09:03:36.215Z'
spec:
volumes:
- name: kube-event-logstash-pipeline-config
configMap:
name: kube-event-logstash-pipeline-config
defaultMode: 420
containers:
- name: kube-event-logstash
image: 'logstash:7.8.0'
env:
- name: XPACK_MONITORING_ELASTICSEARCH_HOSTS
value: 'http://192.168.100.100:8200'
- name: XPACK_MONITORING_ELASTICSEARCH_USERNAME
value: jokerbai
- name: XPACK_MONITORING_ELASTICSEARCH_PASSWORD
value: JeA9BiAgnNRzVrp5JRVQ4vYX
- name: PIPELINE_ID
value: kube-event-logstash
- name: KAFKA_SERVER
value: '192.168.100.50:9092,192.168.100.51:9092,192.168.100.52:9092'
- name: ES_SERVER
value: 'http://192.168.100.100:8200'
- name: ES_USER_NAME
value: jokerbai
- name: ES_USER_PASSWORD
value: JeA9BiAgnNRzVrp5JRVQ4vYX
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: PIPELINE_BATCH_SIZE
value: '4000'
- name: PIPELINE_BATCH_DELAY
value: '100'
- name: PIPELINE_WORKERS
value: '4'
- name: LS_JAVA_OPTS
value: '-Xms2g -Xmx3500m'
resources:
limits:
cpu: '2'
memory: 4Gi
requests:
cpu: '2'
memory: 4Gi
volumeMounts:
- name: kube-event-logstash-pipeline-config
mountPath: /usr/share/logstash/pipeline
livenessProbe:
tcpSocket:
port: 9600
initialDelaySeconds: 39
timeoutSeconds: 5
periodSeconds: 30
successThreshold: 1
failureThreshold: 2
readinessProbe:
tcpSocket:
port: 9600
initialDelaySeconds: 39
timeoutSeconds: 5
periodSeconds: 30
successThreshold: 1
failureThreshold: 2
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: IfNotPresent
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
securityContext: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node/category
operator: In
values:
- app
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-event-logstash-pipeline-config
namespace: log
data:
logstash.conf: |-
input {
kafka {
id => "kafka_plugin_id"
bootstrap_servers => "${KAFKA_SERVER}"
client_id => "logstash"
group_id => "logstash"
decorate_events => true
topics => ["kubenetes-event"]
codec => json {
charset => "UTF-8"
}
}
}
output {
elasticsearch {
hosts => "${ES_SERVER}"
user => "${ES_USER_NAME}"
password => "${ES_USER_PASSWORD}"
index => "kubernetes-event-%{+YYYY.MM}"
manage_template => false
template_name => "kubernetes-event"
}
}
部署之前,先在ES中创建template,可以在kibana中的dev tools中进行操作,语句如下:
PUT _template/kubernetes-event
{
"index_patterns" : [
"*kubernetes-event*"
],
"settings": {
"index": {
"highlight": {
"max_analyzed_offset": "10000000"
},
"number_of_shards": "2",
"number_of_replicas": "0"
}
},
"mappings": {
"properties": {
"cluster": {
"type": "keyword"
},
"kind": {
"type": "keyword"
},
"message": {
"type": "text"
},
"name": {
"type": "keyword"
},
"namespace": {
"type": "keyword"
},
"reason": {
"type": "keyword"
},
"type": {
"type": "keyword"
},
"timestamp": {
"type": "keyword"
}
}
},
"aliases": {}
}
然后再在Kubernetes集群中部署Logstash。然后就可以在Kibana上查看收集到的事件了,如下:
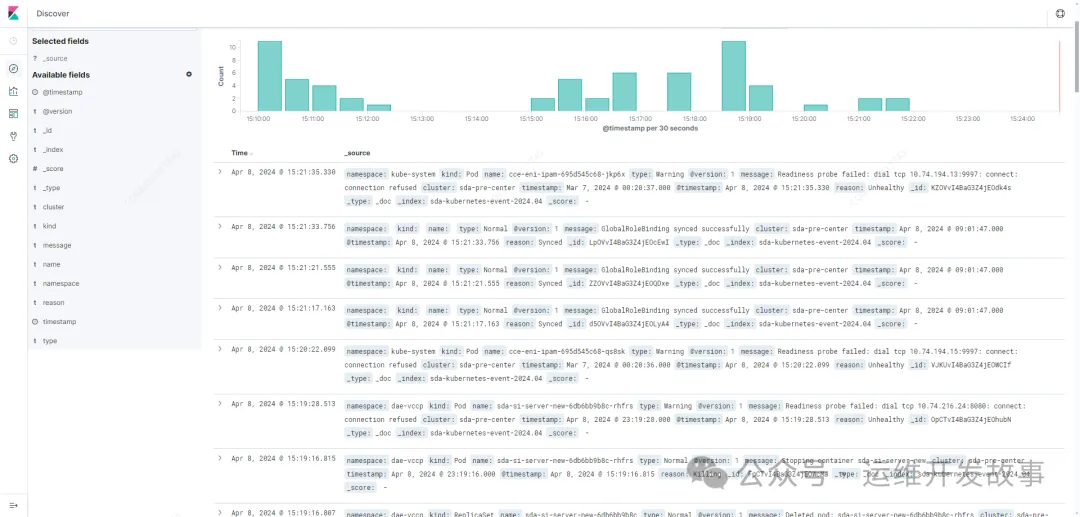
只要数据有了,不论是查询还是做分析,都变得简单容易了。比如最简单得统计今天事件原因为Unhealthy所发生的总次数,可以在Kibana中创建图表,如下:
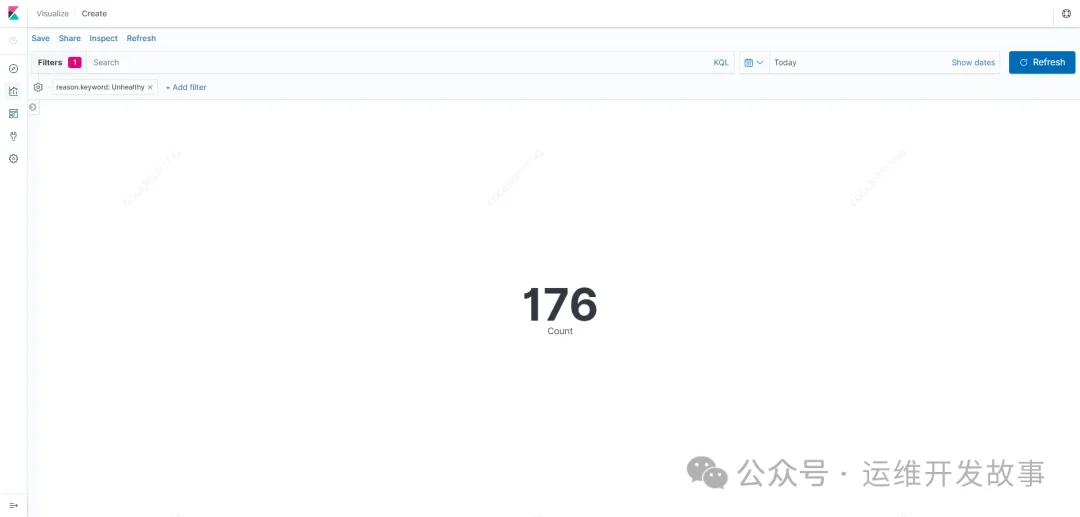
以上就是在Kubernetes中对集群事件进行收集和告警,这是站在巨人的肩膀上直接使用。在企业中还可以对其进行二次开放以将功能更丰富,比如支持对事件告警增加开关,可以任意开启或者关闭某个事件告警。
评论区