

什么是 SLI/SLO
SLI,全名 Service Level Indicator,是服务等级指标的简称,它是衡定系统稳定性的指标。
SLO,全名 Sevice Level Objective,是服务等级目标的简称,也就是我们设定的稳定性目标,比如 "4 个 9","5 个 9" 等。
SRE 通常通过这两个指标来衡量系统的稳定性,其主要思路就是通过 SLI 来判断 SLO,也就是通过一系列的指标来衡量我们的目标是否达到了 "几个 9"。
如何选择 SLI
在系统中,常见的指标有很多种,比如:
- 系统层面:CPU 使用率、内存使用率、磁盘使用率等
- 应用服务器层面:端口存活状态、JVM 的状态等
- 应用运行层面:状态码、时延、QPS 等
- 中间件层面:QPS、TPS、时延等
- 业务层面:成功率、增长速度等
这么多指标,应该如何选择呢?只要遵从两个原则就可以:
- 选择能够标识一个主体是否稳定的指标,如果不是这个主体本身的指标,或者不能标识主体稳定性的,就要排除在外。
- 优先选择与用户体验强相关或用户可以明显感知的指标。
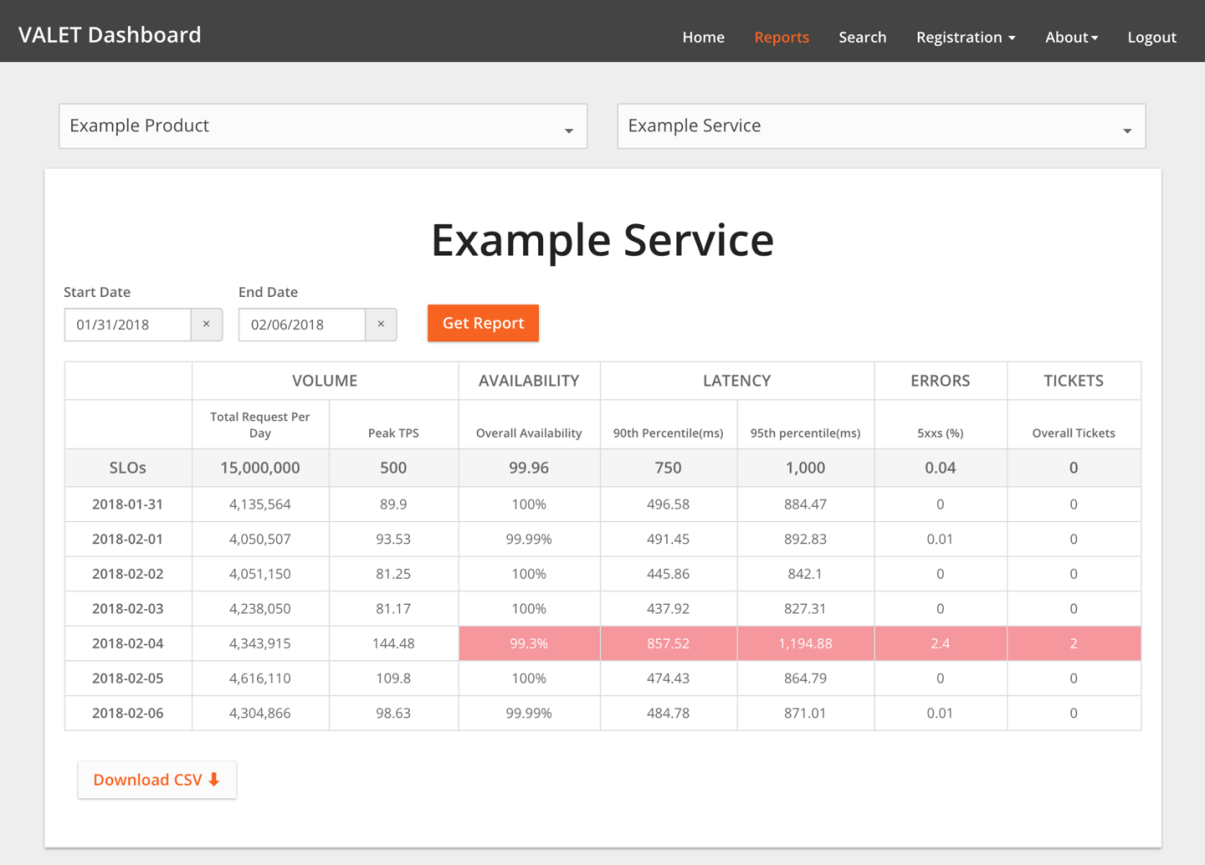
通常情况下,可以直接使用谷歌的 VALET 指标方法。
- V:Volume,容量,服务承诺的最大容量
- A:Availability,可用性,服务是否正常
- L:Latency,延迟,服务的响应时间
- E:Error,错误率,请求错误率是多少
- T:Ticket,人工介入,是否需要人工介入
这就是谷歌使用 VALET 方法给多的样例。
上面仅仅是简单的介绍了一下 SLI/SLO,更多的知识可以学习《SRE:Google 运维解密》和赵成老师的极客时间课程《SRE 实践手册》。下面来简单介绍如何使用 Prometheus 来进行 SLI/SLO 监控。
service-level-operator
Service level operator 是为了 Kubernetes 中的应用 SLI/SLO 指标来衡量应用的服务指标,并可以通过 Grafana 来进行展示。
Operator 主要是通过 SLO 来查看和创建新的指标。例如:
apiVersion: monitoring.spotahome.com/v1alpha1
kind: ServiceLevel
metadata:
name: awesome-service
spec:
serviceLevelObjectives:
- name: "9999_http_request_lt_500"
description: 99.99% of requests must be served with <500 status code.
disable: false
availabilityObjectivePercent: 99.99
serviceLevelIndicator:
prometheus:
address: http://myprometheus:9090
totalQuery: sum(increase(http_request_total{host="awesome_service_io"}[2m]))
errorQuery: sum(increase(http_request_total{host="awesome_service_io", code=~"5.."}[2m]))
output:
prometheus:
labels:
team: a-team
iteration: "3"
- availabilityObjectivePercent:SLO
- totalQuery:总请求数
- errorQuery:错误请求数
Operator 通过 totalQuert 和 errorQuery 就可以计算出 SLO 的指标了。
部署 service-level-operator
前提:在 Kubernetes 集群中部署好 Prometheus,我这里是采用 Prometheus-Operator 方式进行部署的。
(1)首先创建 RBAC
apiVersion: v1
kind: ServiceAccount
metadata:
name: service-level-operator
namespace: monitoring
labels:
app: service-level-operator
component: app
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: service-level-operator
labels:
app: service-level-operator
component: app
rules:
# Register and check CRDs.
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- "*"
# Operator logic.
- apiGroups:
- monitoring.spotahome.com
resources:
- servicelevels
- servicelevels/status
verbs:
- "*"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: service-level-operator
subjects:
- kind: ServiceAccount
name: service-level-operator
namespace: monitoring
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: service-level-operator
(2)然后创建 Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: service-level-operator
namespace: monitoring
labels:
app: service-level-operator
component: app
spec:
replicas: 1
selector:
matchLabels:
app: service-level-operator
component: app
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
app: service-level-operator
component: app
spec:
serviceAccountName: service-level-operator
containers:
- name: app
imagePullPolicy: Always
image: quay.io/spotahome/service-level-operator:latest
ports:
- containerPort: 8080
name: http
protocol: TCP
readinessProbe:
httpGet:
path: /healthz/ready
port: http
livenessProbe:
httpGet:
path: /healthz/live
port: http
resources:
limits:
cpu: 220m
memory: 254Mi
requests:
cpu: 120m
memory: 128Mi
(3)创建 service
apiVersion: v1
kind: Service
metadata:
name: service-level-operator
namespace: monitoring
labels:
app: service-level-operator
component: app
spec:
ports:
- port: 80
protocol: TCP
name: http
targetPort: http
selector:
app: service-level-operator
component: app
(4)创建 prometheus serviceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: service-level-operator
namespace: monitoring
labels:
app: service-level-operator
component: app
prometheus: myprometheus
spec:
selector:
matchLabels:
app: service-level-operator
component: app
namespaceSelector:
matchNames:
- monitoring
endpoints:
- port: http
interval: 10s
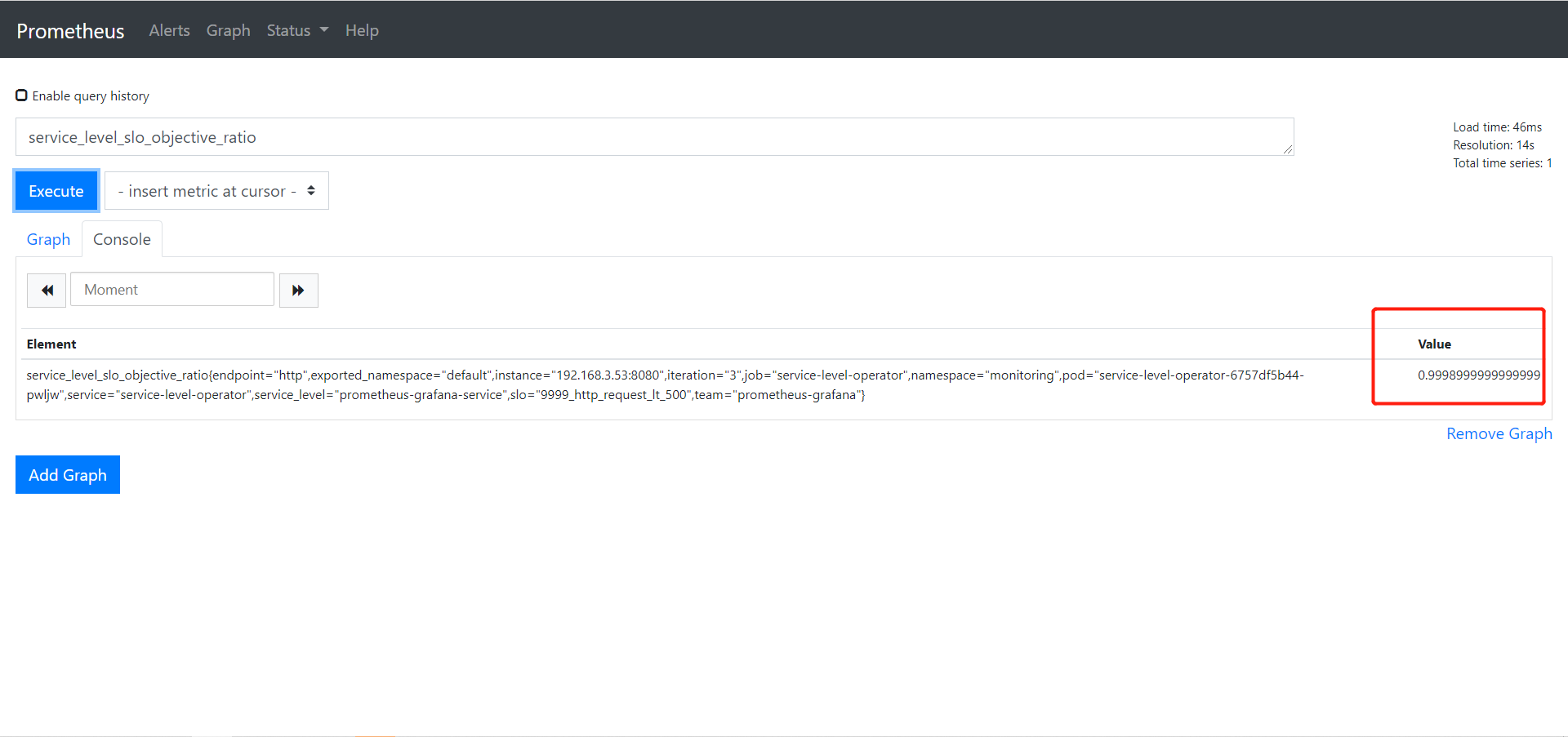
到这里,Service Level Operator 部署完成了,可以在 prometheus 上查看到对应的 Target,如下:

然后就需要创建对应的服务指标了,如下所示创建一个示例。
apiVersion: monitoring.spotahome.com/v1alpha1
kind: ServiceLevel
metadata:
name: prometheus-grafana-service
namespace: monitoring
spec:
serviceLevelObjectives:
- name: "9999_http_request_lt_500"
description: 99.99% of requests must be served with <500 status code.
disable: false
availabilityObjectivePercent: 99.99
serviceLevelIndicator:
prometheus:
address: http://prometheus-k8s.monitoring.svc:9090
totalQuery: sum(increase(http_request_total{service="grafana"}[2m]))
errorQuery: sum(increase(http_request_total{service="grafana", code=~"5.."}[2m]))
output:
prometheus:
labels:
team: prometheus-grafana
iteration: "3"
上面定义了 grafana 应用 "4 个 9" 的 SLO。
然后可以在 Prometheus 上看到具体的指标,如下。
接下来在 Grafana 上导入 ID 为 8793 的 Dashboard,即可生成如下图表。
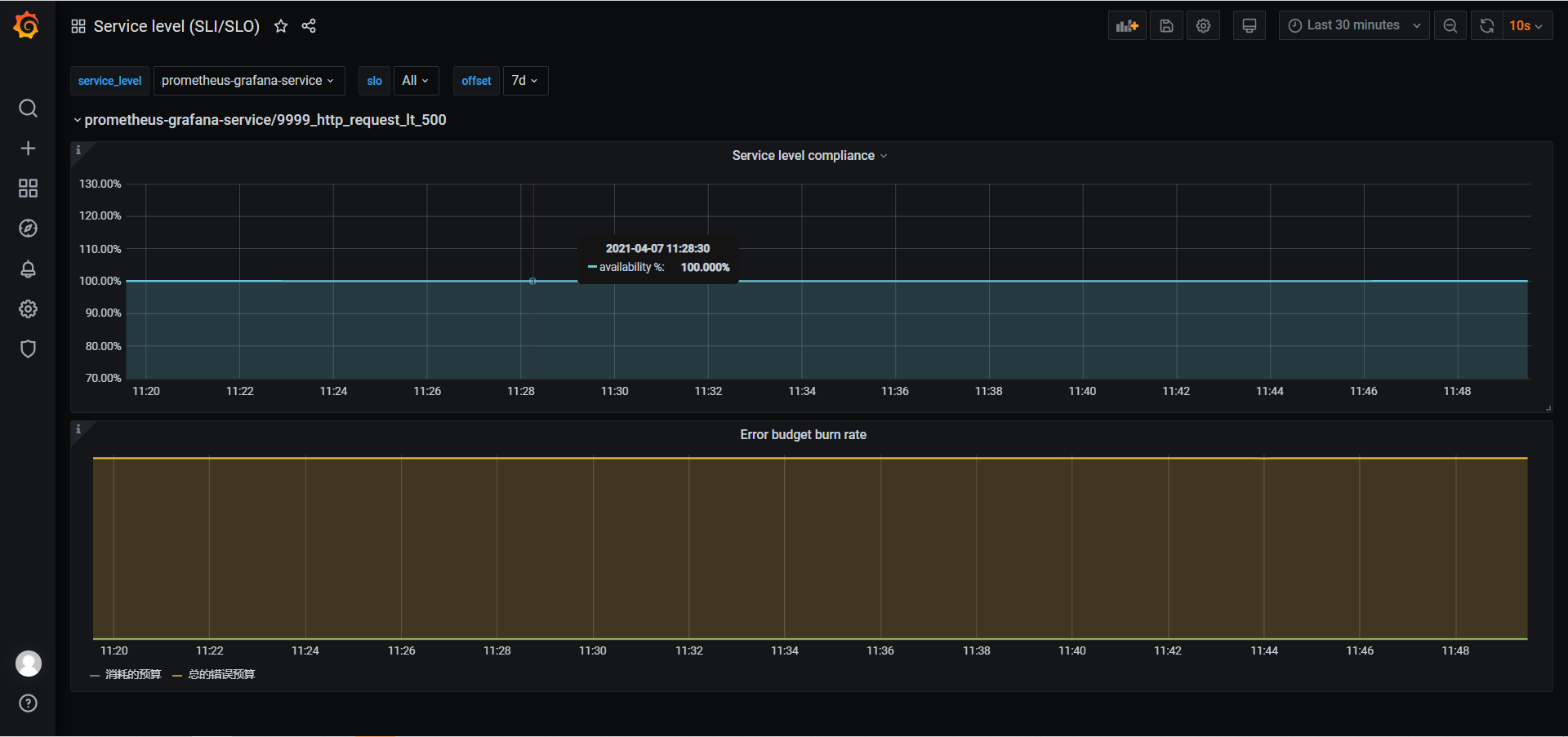
上面是 SLI,下面是错误总预算和已消耗的错误。
下面可以定义告警规则,当 SLO 下降时可以第一时间收到,比如:
groups:
- name: slo.rules
rules:
- alert: SLOErrorRateTooFast1h
expr: |
(
increase(service_level_sli_result_error_ratio_total[1h])
/
increase(service_level_sli_result_count_total[1h])
) > (1 - service_level_slo_objective_ratio) * 14.6
labels:
severity: critical
team: a-team
annotations:
summary: The monthly SLO error budget consumed for 1h is greater than 2%
description: The error rate for 1h in the {{$labels.service_level}}/{{$labels.slo}} SLO error budget is being consumed too fast, is greater than 2% monthly budget.
- alert: SLOErrorRateTooFast6h
expr: |
(
increase(service_level_sli_result_error_ratio_total[6h])
/
increase(service_level_sli_result_count_total[6h])
) > (1 - service_level_slo_objective_ratio) * 6
labels:
severity: critical
team: a-team
annotations:
summary: The monthly SLO error budget consumed for 6h is greater than 5%
description: The error rate for 6h in the {{$labels.service_level}}/{{$labels.slo}} SLO error budget is being consumed too fast, is greater than 5% monthly budget.
第一条规则表示在 1h 内消耗的错误率大于 30 天内的 2%,应该告警。第二条规则是在 6h 内的错误率大于 30 天的 5%,应该告警。
下面是谷歌的的基准。
| SLO 错误率 | 时间范围 | 30 天消耗百分比 |
|---|---|---|
| 2% | 1h | 730 * 2 / 100 = 14.6 |
| 5% | 6h | 730 / 6 * 5 / 100 = 6 |
| 10% | 3d | 30 / 3 * 10 / 100 = 1 |
最后
说到系统稳定性,这里不得不提到系统可用性,SRE 提高系统的稳定性,最终还是为了提升系统的可用时间,减少故障时间。那如何来衡量系统的可用性呢?
目前业界有两种衡量系统可用性的方式,一个是时间维度,一个是请求维度。时间维度就是从故障出发对系统的稳定性进行评估。请求维度是从成功请求占比的角度出发,对系统稳定性进行评估。
- 时间维度:可用性 = 服务时间 / (服务时间 + 故障时间)
- 请求维度:可用性 = 成功请求数 / 总请求数
在 SRE 实践中,通常会选择请求维度来衡量系统的稳定性,就如上面的例子。不过,如果仅仅通过一个维度来判断系统的稳定性也有点太武断,还应该结合更多的指标,比如延迟,错误率等,而且对核心应用,核心链路的 SLI 应该更细致。
参考
[1] 《SRE 实践手册》- 赵成
[2] 《SRE:Google 运维解密》
[3] https://github.com/spotahome/service-level-operator