

监控是方法,告警是手段,解决是目的。
但是,大家有没有遇到这种困惑。我收集了一大堆指标,但是我不知道哪些指标应该告警,也不知道如何把这些告警发送到对应的团队或者个人,更不知道如何做告警升级。
我之前用 Prometheus+Altermanager 这一套的时候,为每个团队弄一个钉钉群,然后打了一堆的标签,匹配不同的标签发送到不同的群,如果要做告警升级的话,很多时候都是通过阈值升级来完成,但是同一个告警通过时间来升级就不好办。
但是夜莺在做告警规则管理就没那么复杂(复杂的事情他们给你做了),而且还很优雅。我在《【夜莺监控】初识夜莺,还是强!》提到过:Grafana 更擅长监控面板的管理,N9e 更擅长告警规则的管理。
今天,我们就来看看夜莺到底是怎么玩的。
告警规则
兵马未动,粮草先行。
要告警,得先知道我们的需求是什么,也就是要弄明白哪些指标需要告警。
比如说,在系统层面,我们要考虑 CPU、内存、磁盘、IO 等指标;在应用层面,我们要考虑应用的饱和度、失败率以及延迟等;在业务层面,我们要考虑这次的交易失败次数、哪里失败等。
站在不同的层面,考虑的监控指标以及告警策略会不一样。我在之前的《关于监控那些事,你有必要了解一下》和《系统性能指标:洞察系统运行的关键脉搏》两篇文章中有一些个人的见解,感兴趣的同学可以看一下。
夜莺的告警规则分为内置规则和自定义规则。
内置规则旨在降低大家的使用门槛,为大家提供一套普适性的规则。主要有以下内容: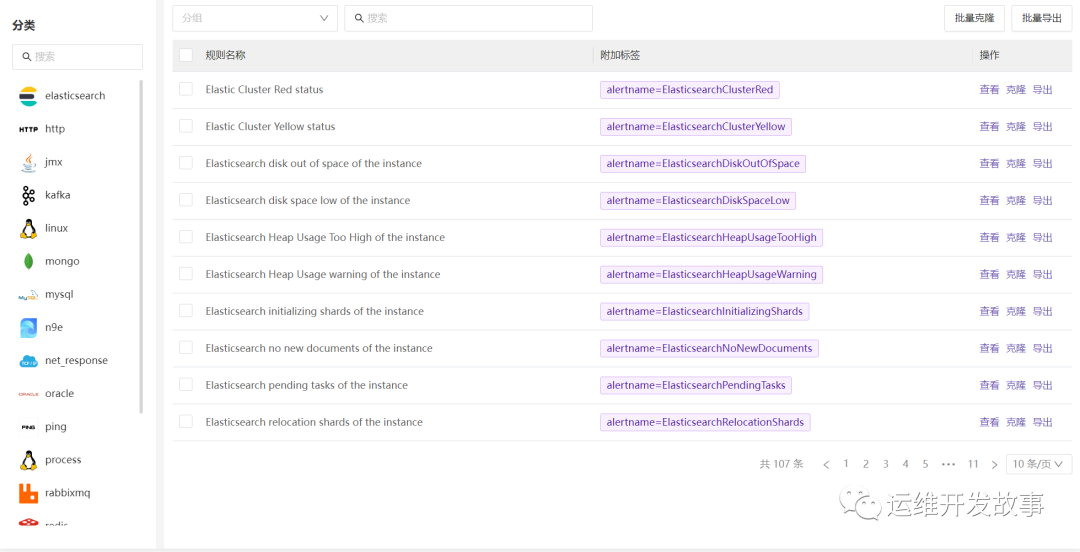
内置的告警规则不会生效,除非你把它拉到你的规则里。如果你看中了某个规则,就可以把它克隆到生效规则中。比如,我把 Linux TIME_WAIT 告警规则克隆到默认业务组中。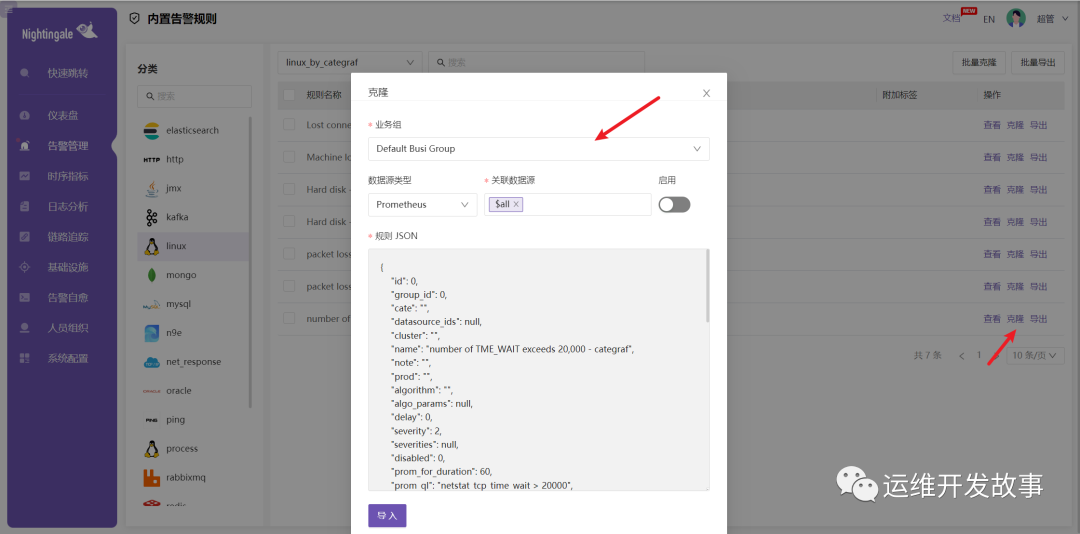
然后到告警规则总览里就能看到默认业务组中新增了一条告警规则。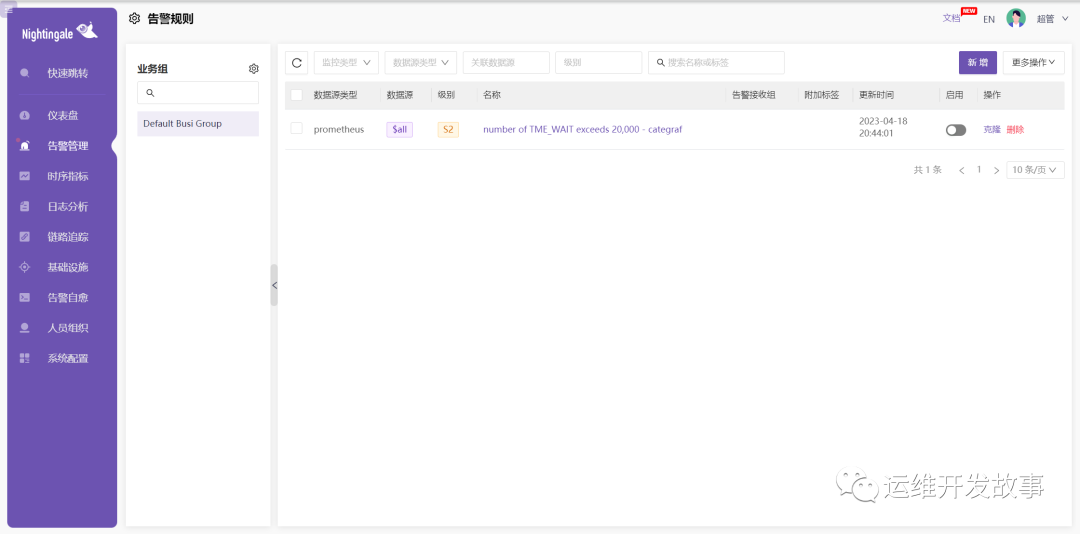
看到这里,脑海里是否有一点灵感了?
我们可以根据实际情况创建多个业务组,然后是否就可以把涉及到多个业务组的告警规则进行分开管理了?
假设我们有前台以及中台两个团队,就可以把指标分别归类。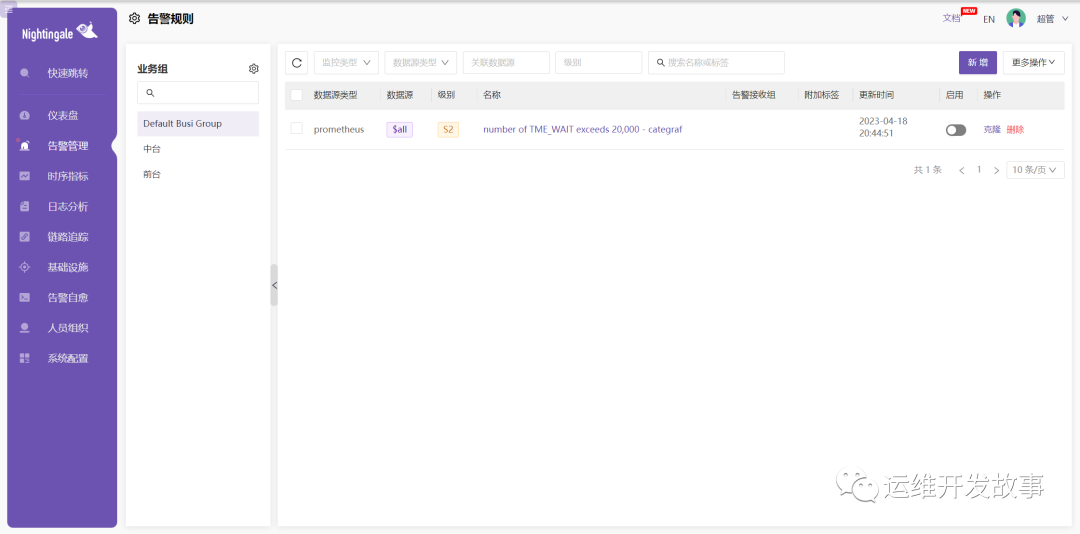
默认导入进来的规则原则上是没有生效的,需要做一些额外配置。
点开告警规则名称,进入配置页面。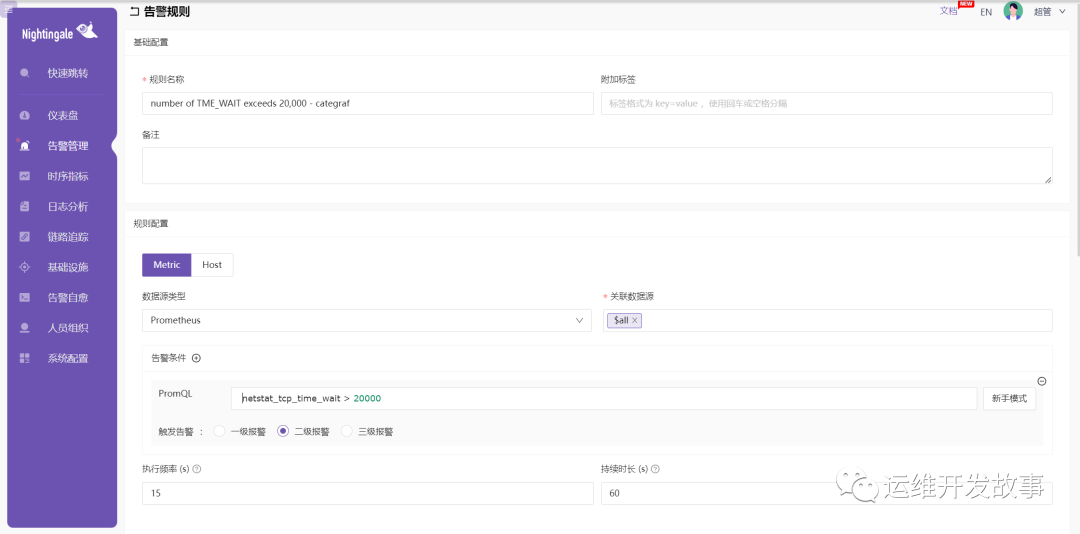
我们可以自定义告警条件、数据源、告警等级等配置。如上我们配置的信息归纳如下:
- 告警的数据源是 local_prometheus,这表示你的告警来自哪个集群。
- 告警条件是当 TIME_WAIT 总数大于 20000 才会触发告警。
- 告警等级是二级,也就是一般重要等级。
- 执行频率是每 15 秒执行一次,连续持续 60s 依然满足告警规则,则会触发告警
接下来就是额外的配置了,如下: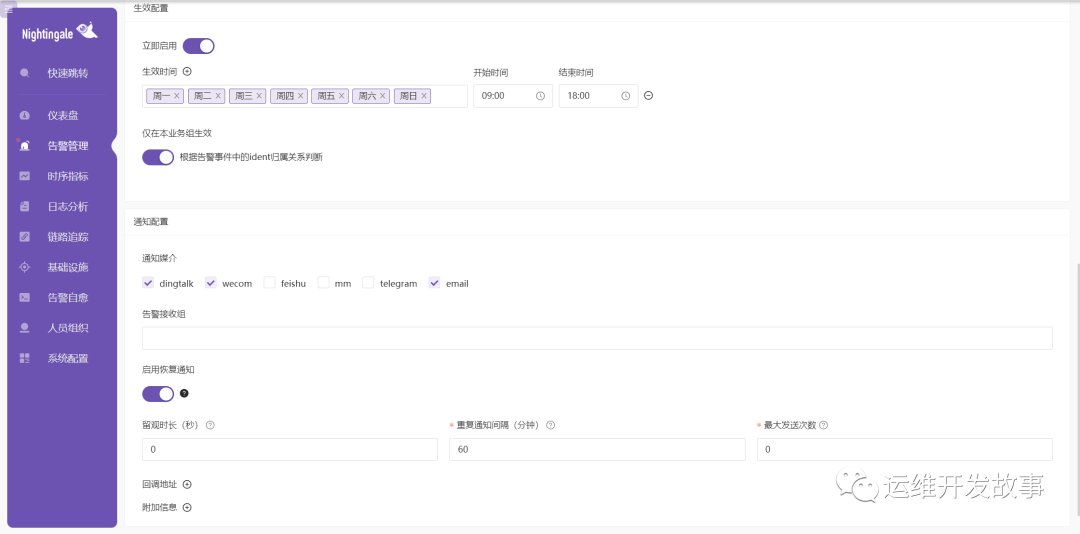
生效配置用来配置改告警规则在什么时间段,什么业务组生效。而通知配置则是配置通知媒介,也就是如果产生了告警,应该通过哪些渠道发到哪些地方。
不过,在通知配置处还可以做额外的配置:
- 启动恢复通知,也就是如果告警恢复了,也会通过这个渠道告知负责人。
- 告警接受组,也就是业务组。
- 留观时长,当告警恢复后,观察多长时间才给业务组发恢复通知。可以规避哪些波动性的告警,一会发告警,一会发恢复等问题。
- 重复通知,也就是在这个时间段里,如果还未解决告警,就会再发送一次。当然,这里还不涉及告警升级。
看到这里,有没有对普通的告警规则管理有一定的认识了?
除了克隆内置的告警规则,我们还可以自定义告警规则,不过整体上的配置和上面是一样的。
屏蔽告警
一般被屏蔽的告警都不是很重要的告警。
那在什么情况下会屏蔽告警呢?
比如我们在做应用发版的时候,难免会遇到问题,这时候可以提前做一些屏蔽规则,以免产生告警信息。
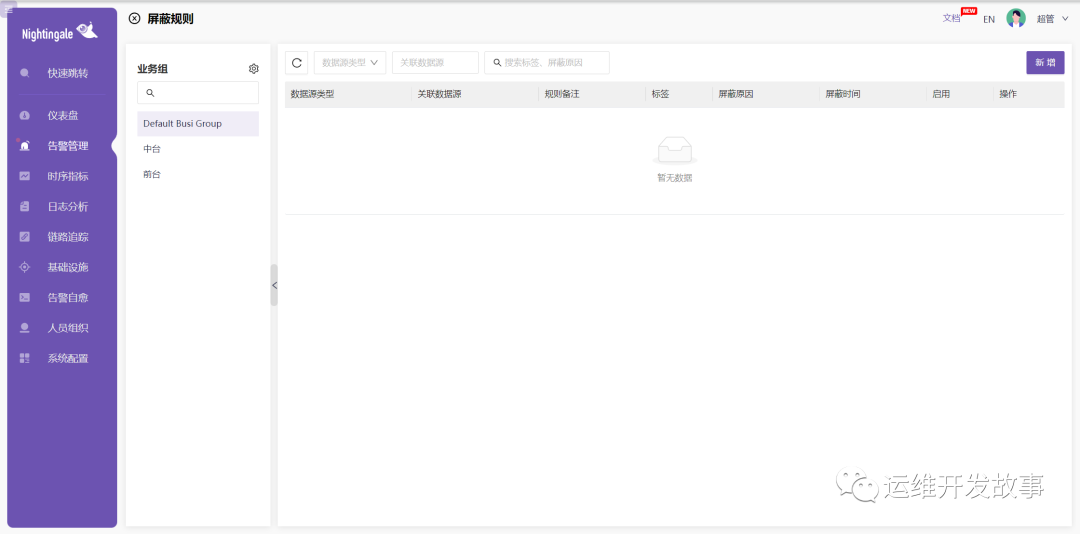
屏蔽规则也是按业务组分的,我们可以新增一条规则,如下创建一条屏蔽消息中心告警的规则。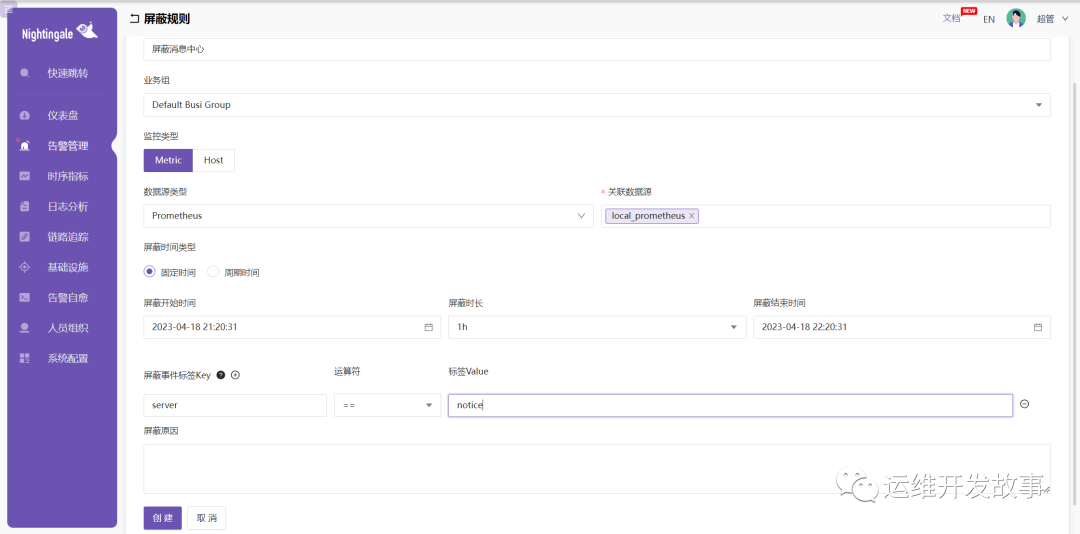
这样在固定的时间窗口内,告警信息不同发送。
有的同学可能要说了,这样一个一个添加,是不是稍显麻烦?
如果是已经产生的活跃告警,可以一键屏蔽。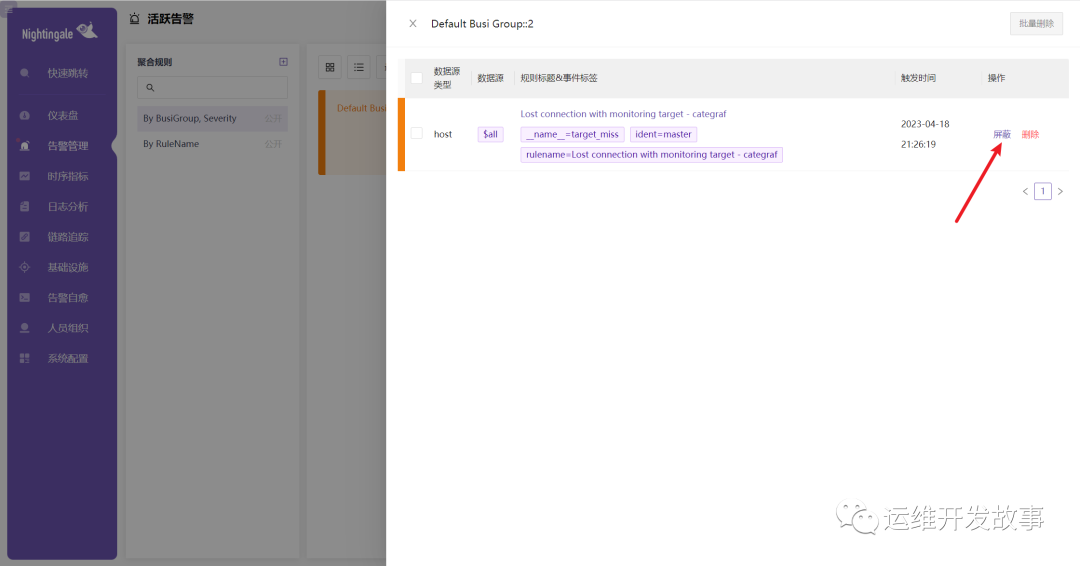
如果是历史告警,也可以一键屏蔽。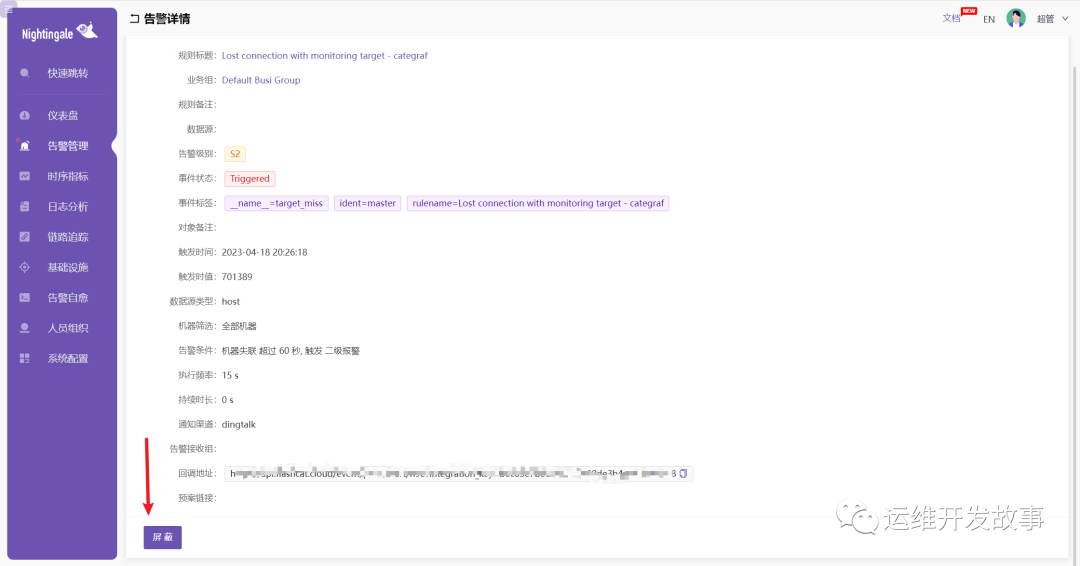
除此之外呢?
想屏蔽啥,就自己加吧!
告警升级
如果一个告警在一段时间内还没进行处理,怎么办?
要么不是重要的告警——把规则删了吧,留之无用。
要么是解决不了的告警——升级吧,然更多人知道。
在夜莺中,在订阅规则中可以实现告警升级。
比如,我们配置如下: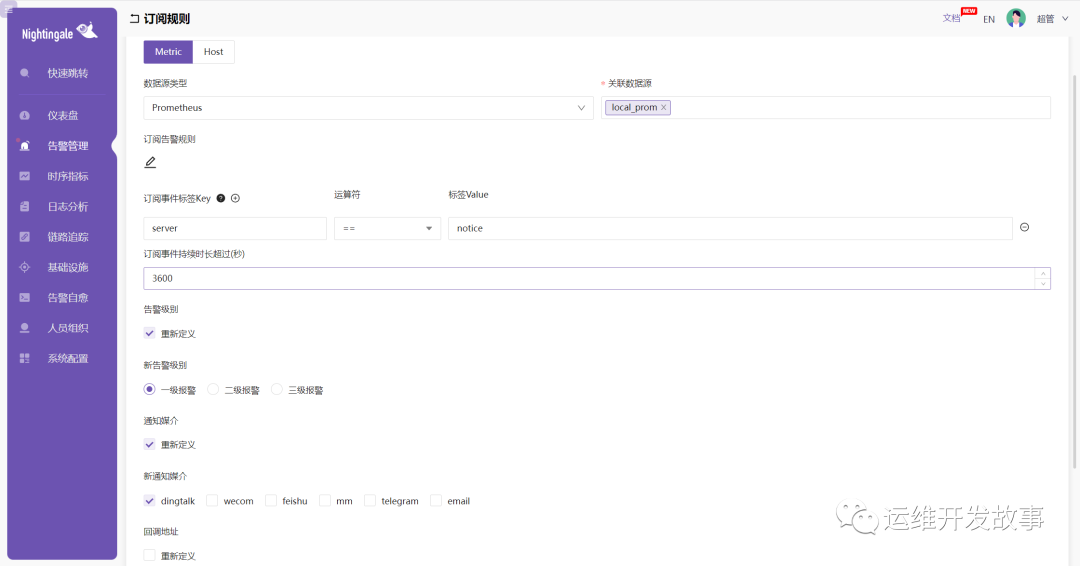
如果 server=notice 的告警事件在 1 小时内还未解决,我们将告警等级升级为一级,并且将告警信息发送到更高级别的群里。
这里的规则也可以按业务团队来进行分类管理。
除此之外还提供活跃告警和历史告警,可以查看当前有哪些告警信息,以及历史的告警记录。
告警自愈
从事运维越久,其实会发现很多事情的处理都是重复性的,一些简单重复的工作可以通过自动化脚本来进行处理,不仅能提升工作效率,也能在一定程度上降低人为操作的风险。
夜莺提供了告警自愈功能。功能虽好,可不好贪杯哦。
处理一个告警,一定要先弄清楚背后的真正原因,这样才能解决问题。所以对于告警自愈,一定要明白你做的这个自动化操作的风险很低并且实验了很多次。不要存在 cd /opt/aaa;rm -rf ./ 的操作。
在夜莺中,使用 ibex 模板来实现告警自愈。目前 ibex-server 端需要自己部署,ibex-agent 端已经集成到 Categraf 中去了。
部署 ibex-server
到 https://github.com/flashcatcloud/ibex/releases 下载二进制包,下载下来过后里面有以下文件:
# ll
total 21536
drwxr-xr-x 3 root root 4096 Apr 19 10:44 etc
-rwxr-xr-x 1 root root 16105472 Nov 15 2021 ibex
-rw------- 1 root root 5931963 Jun 3 2022 ibex-1.0.0.tar.gz
drwxr-xr-x 2 root root 4096 Nov 15 2021 sql
导入数据库:
mysql -uroot -p <sql/ibex.sql
然后修改 /etc/server.conf 配置文件,主要修改数据库的配置。
最后启动服务端:
nohup ./ibex server &> server.log &
配置客户端
在系统配置 -> 通知配置 -> 告警自愈模块配置对应的服务端地址: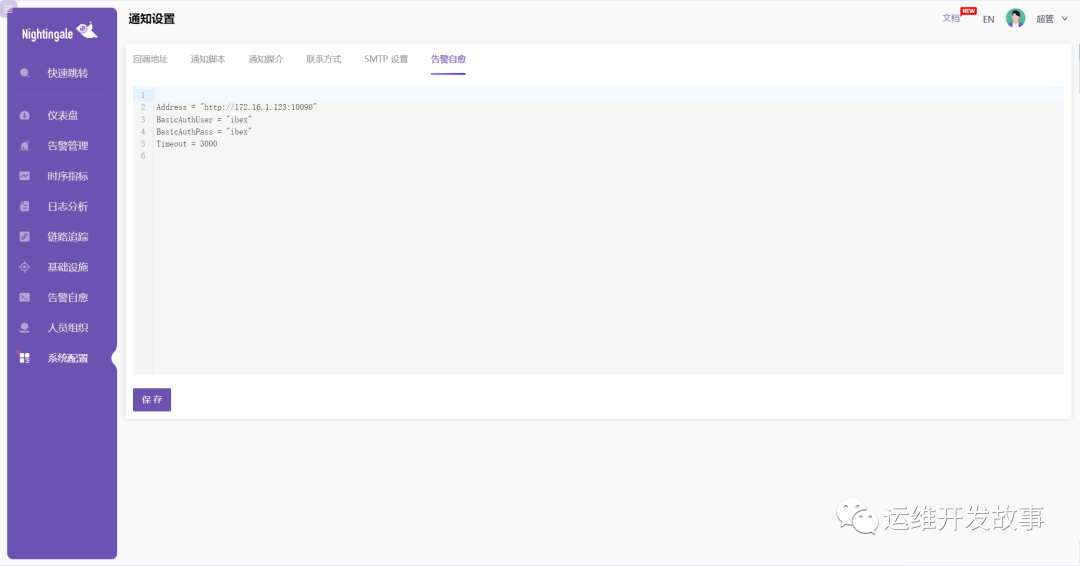
测试自愈
然后到告警自愈 -> 自愈脚本处添加脚本,如下: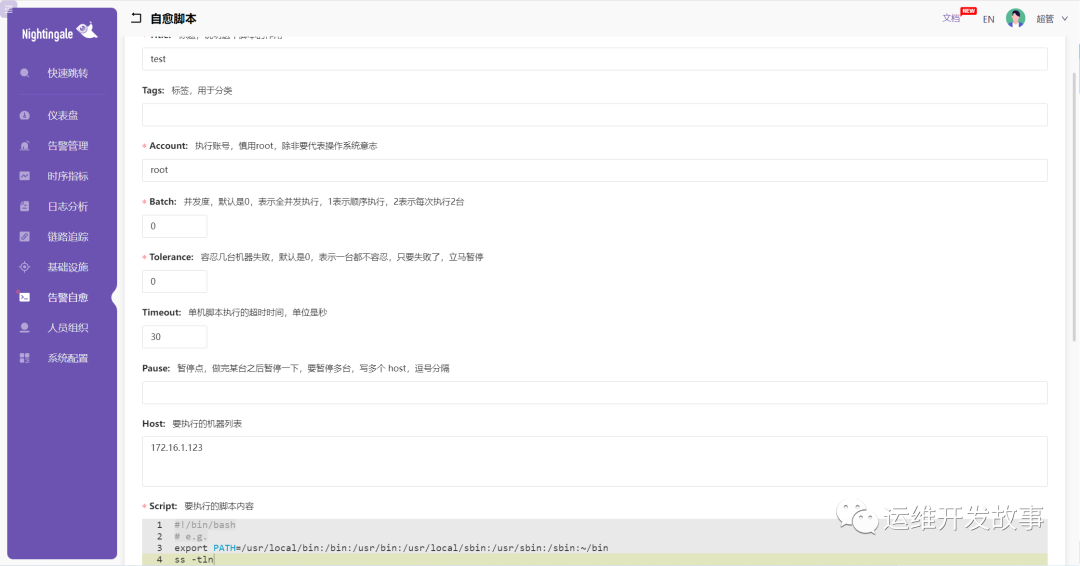
保存退出,点击创建任务: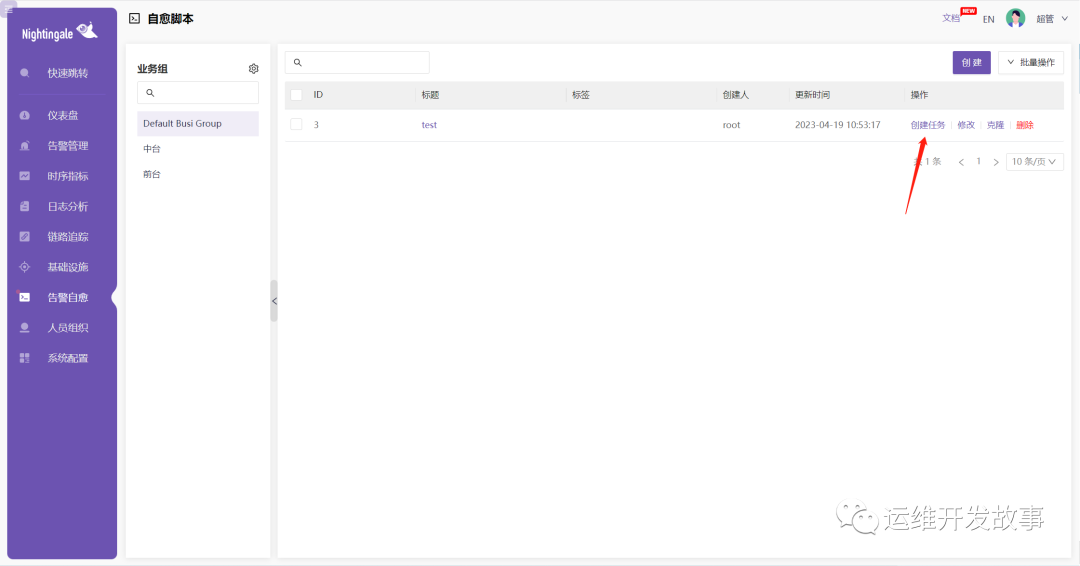
如果里面的配置不需要修改或者修改对应的配置后,选择立即执行: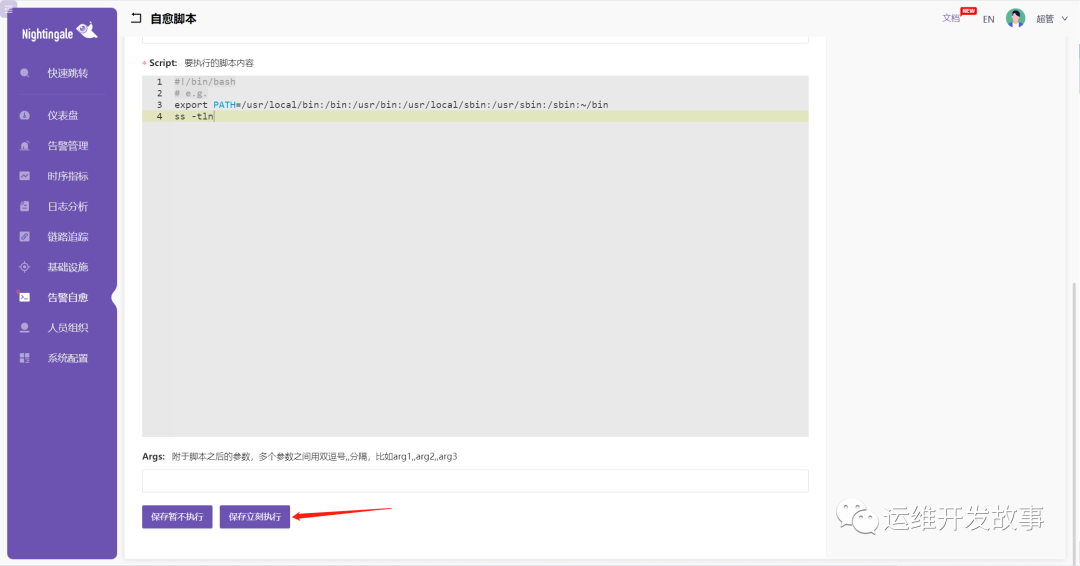
到这,你以为就好了么?
反正我没成功,到这里我不得不吐槽一下这个模块:
- ibex-server 的部署有没有前置条件
- ibex-agent(categraf)有没有前置条件
- 自愈脚本执行失败,不论是客户端还是服务端都没有具体的失败日志
- N9e V6 版本的告警自愈配置入口怎么放到消息通知模块?怪怪的
- 官方文档这个模块有点过于简单
所以,我这里并没有成功,前端抛了超时。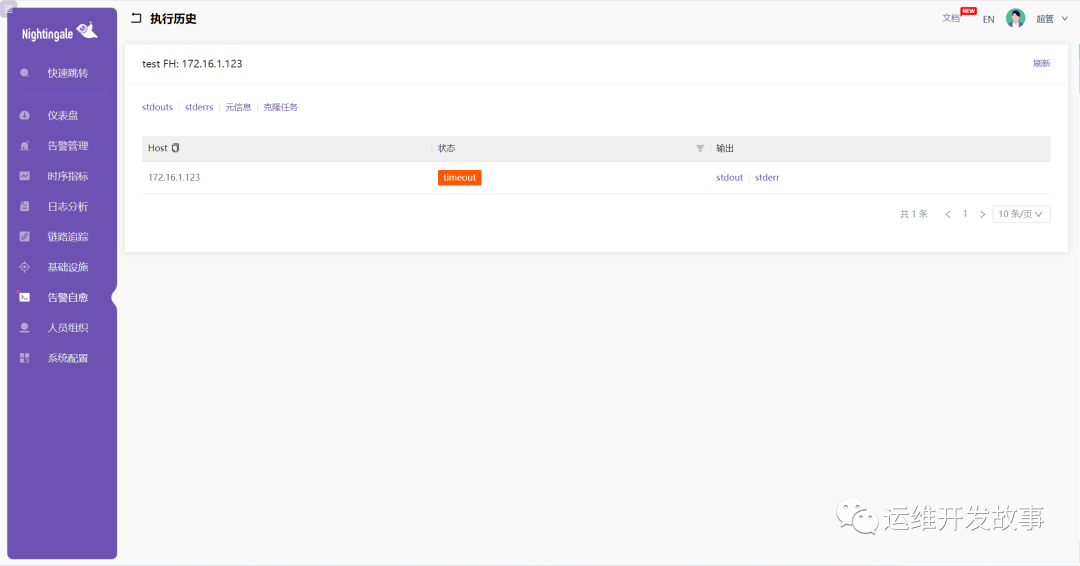
后端没有日志。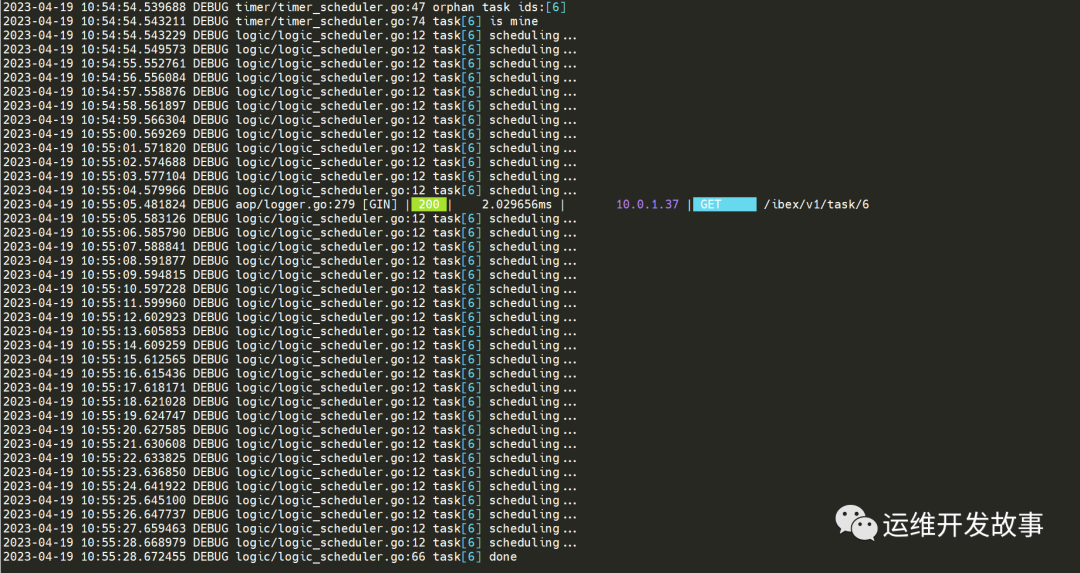
原来,是要到 Categraf 中得配置里配置 ibex-server 的地址,然而这个配置并没有同步更新到 N9e 的 Helm Chart 中,我已经提了 PR 修复了。

配置完上面的模块,就可以再测试故障自愈了。
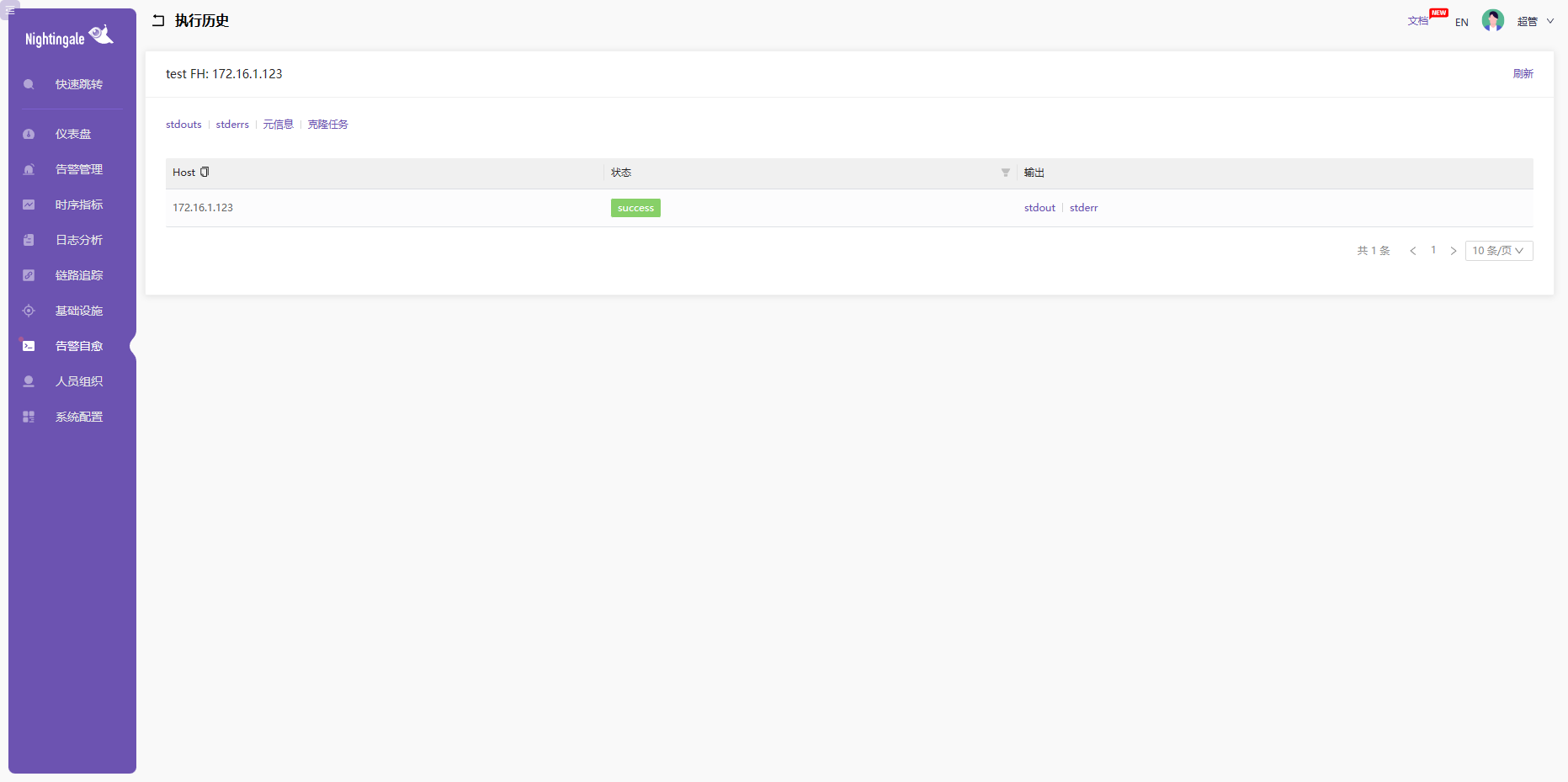
总结
目前夜莺能够比较齐全的实现告警规则的管理,告警渠道分发以及告警消息抑制以及升级,而且 FlashDuty 可以接入不同的集群告警,在大部分企业中以及够用了。
不过还有一些不足:
- N9e 整体模块是使用的 Helm 部署到 K8s 中的
- ibex-server 端却是以二进制的形式直接部署在主机上的