 基于Kubernetes容器平台的容灾方案
基于Kubernetes容器平台的容灾方案
# ✍
# 1. 引言
# 1.1、Kubernetes容器平台简介
Kubernetes是一个开源的容器编排平台,它为部署、扩展和管理容器化应用程序提供了强大的基础设施。作为云原生技术的核心,Kubernetes 能够自动化许多复杂的运维任务,如负载均衡、服务发现和资源分配。它的灵活性和可扩展性使其成为构建现代、可靠和高效的分布式系统的理想选择。
Kubernetes容器平台具有以下几个主要特性:
- 容器化应用管理
Kubernetes专门设计用于管理容器化应用,提供了强大的容器编排能力。它可以自动化容器的部署、扩展和操作,大大简化了应用程序的管理过程。
- 自动化部署和扩展
Kubernetes能够根据资源使用情况自动进行应用的水平扩展,确保应用始终有足够的资源来处理负载。同时,它还支持滚动更新和回滚,使得应用的部署和更新变得更加安全和高效。
- 自愈能力
Kubernetes具有强大的自愈能力。它会持续监控应用的健康状态,当检测到故障时,能够自动重启失败的容器,替换或重新调度出现问题的Pod,保证应用的持续可用性。
- 服务发现和负载均衡
Kubernetes提供内置的服务发现机制和负载均衡功能。它可以自动为容器分配IP地址和DNS名称,并且能够在多个容器实例之间分配网络流量,确保服务的高可用性。
- 存储编排
Kubernetes支持多种类型的存储系统,包括本地存储、网络存储(如NFS)和云存储。它提供了持久化卷(Persistent Volumes)的概念,使得数据的管理和持久化变得更加灵活和可靠。
- 配置管理
通过ConfigMaps和Secrets,Kubernetes提供了强大的配置管理能力。这使得应用程序的配置可以与容器镜像分离,提高了配置的灵活性和安全性。
目前,很多企业都选择应用容器化、容器平台化,充分利用容器平台的灵活性保障业务的稳定性,企业对容器平台也报以很高的期望。但是,容器平台本身并不能解决所有问题,特别是在面对灾难性事件时。为了确保业务的连续性和数据的安全性,企业需要制定完善的容灾方案。这种方案不仅要考虑容器平台的特性,还要结合传统IT基础设施的最佳实践。因此,设计和实施一个基于Kubernetes的全面容灾策略变得尤为重要。
# 1.2、容灾方案的重要性
容灾方案对于任何企业来说都是至关重要的。它不仅能够保护企业免受数据丢失和业务中断的风险,还能确保在面对各种灾难性事件时能够迅速恢复正常运营。在当今复杂的IT环境中,尤其是对于采用Kubernetes这样的先进容器平台的企业而言,一个全面且有效的容灾策略可以成为企业竞争力和可靠性的关键差异化因素。
# 1.2.1、什么是容灾
容灾(Disaster tolerance)是指能够容忍灾难的能力,也可以称为应用的韧性(Resiliency)。对于IT系统来讲,要容忍的灾难类型就包括地震、洪水等自然灾害;软硬件故障;网络或病毒攻击;人为蓄意破坏或者误操作等等。容灾常常与灾难恢复相互混用,可以认为容灾就是灾难恢复的能力。
# 1.2.2、什么是灾难恢复
灾难恢复(Disaster recovery)是指企业将信息系统从灾难造成的故障或瘫痪状态恢复到可正常运行状态的一个过程。对大多数企业来说,IT系统的灾难恢复是实现业务连续性的一个关键,也可以说是一个子集。
容灾能力建设的主要目的,就是在灾难发生的时候,能够保证生产业务系统的不间断运行。因此,对大部分现代化的企业来说,IT系统容灾能力的建设成为了业务连续性管理的核心部分。
# 1.2.3、容灾目标
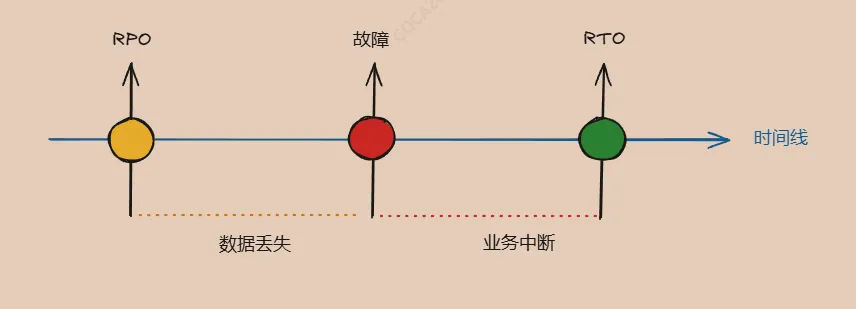
衡量容灾有两个重要的指标:
- RPO(Recovery point objective):自上一个数据恢复点以来可接受的最大时间量。决定可接受的数据丢失或重建。
- RTO(Recovery time objective):服务中断与服务恢复之间可接受的最大延迟时间。决定服务停机的可接受时长。
对于RTO和RPO来说,数值越低表示服务停机的时间和数据丢失量越少,但是越低的RTO和RPO意味着资源成本和运维复性越高。
[[附件/images/d0ac5729cb60da8bded6fad315915237_MD5.jpeg|Open: Pasted image 20241111173108.png]]
# 1.2.4、容灾的策略
常见的容灾策略有冷备、主备、双活三种,不同的策略带来的成本和收益均不同,如下:
[[附件/images/661866aa9dc5173f812f4fb01b587d72_MD5.jpeg|Open: Pasted image 20241111173126.png]]
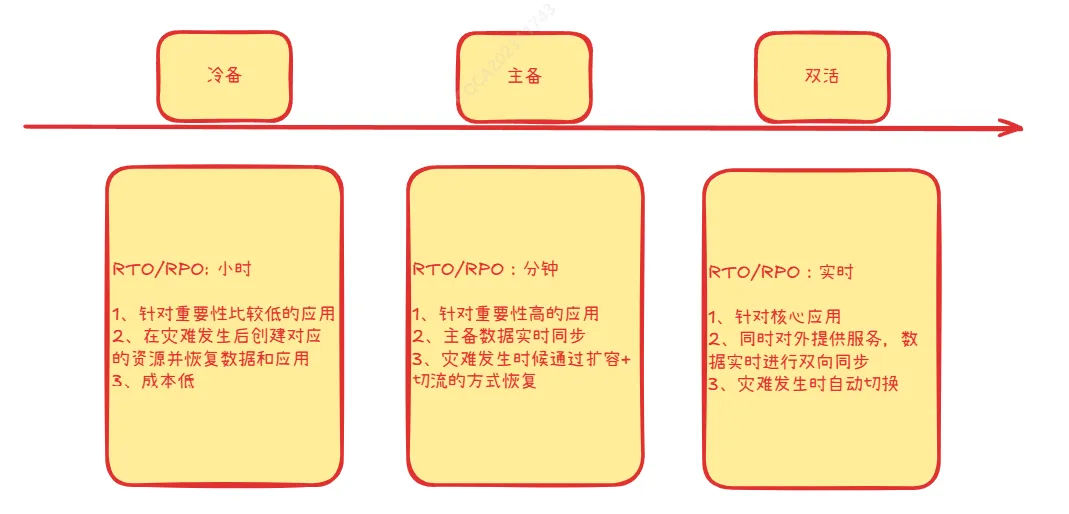
从上图可知:冷备成本较低,但是RTO/RPO较长,不适合重要性较高的应用。主备成本相对冷备有所提升,但是RTO/RPO可达到分钟级别,是大部分企业的首选容灾方式。双活成本就很高,而且对应用、技术的要求也非常高,不过其RTO/RPO接近0,对于对灾难零容忍的应用,也不得不选择双活。
下面用图解的方式,对冷备、主备以及双活三种备份策略做更深一步介绍。
(1)冷备模式
[[附件/images/9afdea4f983dcf9f7da95fe40ce07121_MD5.jpeg|Open: Pasted image 20241111173141.png]]
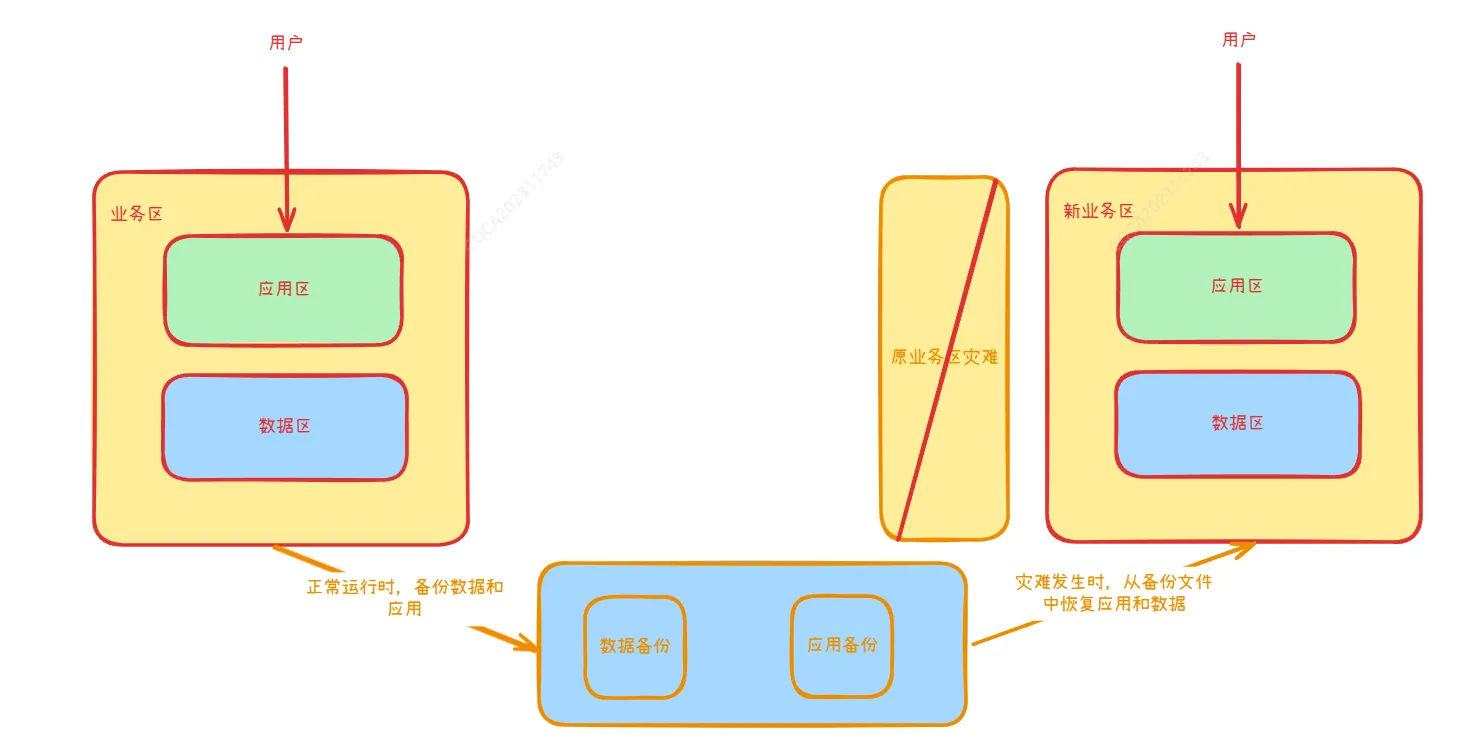
在冷备模式下,系统正常运行时会备份应用和数据,当灾难发生时,系统会将备份的应用和数据在另一个区域进行恢复,并且切换业务流量。
由于冷备模式下的数据无法实时备份,所以在数据恢复时有一定的数据丢失,并且如果数据量较大的时候,恢复时间也会较长。
(2)主备模式
[[附件/images/31d8692c0b106ac1c73094137e6fa333_MD5.jpeg|Open: Pasted image 20241111173154.png]]
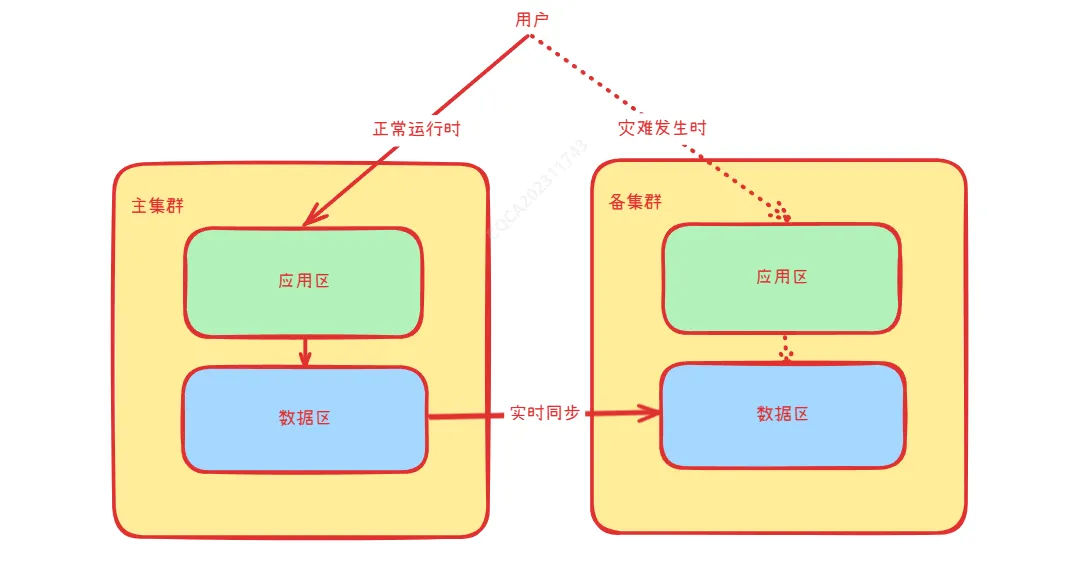
在主备模式下,主集群处理所有的业务流量,备集群用较低的资源运行一份完整的系统,并周期性的发送较少的测试流量到备集群以验证系统的可用性。在灾难发生时候,需要对备集群进行扩容以及数据切换。
(3)双活模式
[[附件/images/2504e7af1aab3389fb4ded80a8c995ca_MD5.jpeg|Open: Pasted image 20241111173205.png]]
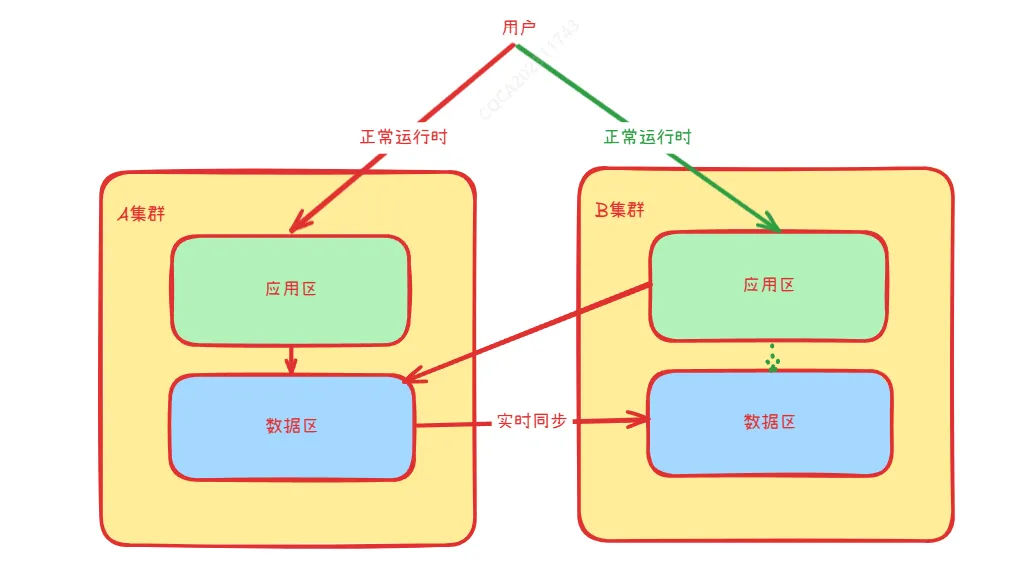
在双活模式下,A\B两个集群都对外提供服务,处理正常的业务流量。当A集群灾难发生时,系统数据库自动进行数据切换,且流量会全部切换到B集群。
- Tips:如果业务流量比较大,在A集群发生灾难后,B集群需要实时进行监控,并且做好随时扩容的准备。
# 1.2.5、容灾方案的关键组成部分
一个有效的容灾方案包含多个关键组成部分,每个部分都在确保系统在面对灾难时能够保持运行或快速恢复方面发挥着重要作用。以下是容灾方案中的几个核心要素:
- 数据备份和恢复
数据是任何系统的生命线,因此有效的数据备份和恢复策略是容灾方案的基石。这包括定期的数据备份、快照创建,以及能够在灾难发生后快速恢复数据的机制。在Kubernetes环境中,这通常涉及使用持久卷(Persistent Volumes)和持久卷声明(Persistent Volume Claims)来管理数据存储,并结合外部存储解决方案来实现数据的备份和复制。
- 持久卷(Persistent Volumes)和持久卷声明(Persistent Volume Claims):
Kubernetes使用持久卷(PV)和持久卷声明(PVC)来管理数据存储。PV是集群中的一块存储,已经被预先配置好,可以是本地磁盘、网络存储(如NFS、iSCSI、云存储等)。PVC是用户对存储资源的请求,它指定了存储的大小、访问模式等要求。通过PVC,用户可以申请所需的存储资源,Kubernetes会自动匹配合适的PV来满足用户的需求。当PVC与PV绑定后,PV将专门为该PVC服务,直到PVC被删除。 - 数据备份:
Kubernetes的资源配置可以导出为YAML格式的文本文件,这些文件可以被看作是系统的“DNA”。通过导出所有资源配置,可以达成全面备份资源配置的目的。这可以通过kubectl命令来实现,例如使用kubectl get deploy -o yaml > deploy.yaml来导出部署资源的配置。 - 数据恢复:数据恢复是从已备份的数据副本恢复到正在运行的
Kubernetes系统。这些数据副本可以是之前备份导出的YAML格式文本文件。数据恢复可以是全量恢复,也可以是部分恢复。全量恢复是从某个时刻的全量备份数据恢复至Kubernetes系统,而部分恢复只恢复部分数据。数据恢复应当记录详细的日志,以便事后查询、审计。 - 卷快照和恢复:
Kubernetes支持卷快照功能,允许用户创建持久卷的快照并从快照中恢复卷。这一功能仅支持CSI卷插件,并且从Kubernetes v1.20版本开始稳定支持。 - 外部存储解决方案:在
Kubernetes环境中,可以结合外部存储解决方案来实现数据的备份和复制。例如,可以使用网络文件系统(NFS)或其他云存储服务来提供持久化存储,并实现数据的备份和恢复。 - 数据同步:为了确保数据的一致性和可用性,可以使用数据同步工具来实现数据的实时同步。
- 应用的高可用
- 多副本部署:通过在
Kubernetes中部署多个应用副本,确保即使某个实例失败,其他副本仍然可以继续提供服务。这可以通过设置Deployment或StatefulSet资源的replicas字段来实现。 - 跨区域复制:在地理上分布的多个数据中心之间复制数据和应用,可以在一个区域发生故障时,迅速切换到另一个区域,确保业务的连续性。
Kubernetes可以通过设置跨区域的集群和复制策略,实现应用的跨区域部署和数据同步。 - 高可用控制平面:
Kubernetes的控制平面(包括API服务器、调度器和控制器管理器)是集群的“大脑”,其高可用性至关重要。通过部署多个控制平面节点,并使用负载均衡器将请求分发到这些节点,可以实现控制平面的高可用。常用的工具包括haproxy和keepalived,它们可以确保控制平面节点的故障切换和负载均衡。 - 自动化故障切换:通过自动化监控和故障切换机制,
Kubernetes能够在组件发生故障时自动恢复,例如,通过健康检查和自动重启失败的Pods来实现
- 网络冗余
- 网络组件的冗余部署:
Kubernetes网络组件(如Calico、Flannel等)通常在网络层面也会有相应的高可用方案,比如多节点部署和配置冗余路由规则等,以确保网络的稳定性和可靠性。 - 负载均衡与故障转移:通过
Keepalived和HAproxy实现的负载均衡层,不仅能够分散对API Server的请求,还能在主节点故障时自动进行故障转移,确保服务的连续性。 - 多可用区部署:在阿里云的一个地域(Region)通常会包含多个可用区(AZ),可用区是电力和网络互相独立的物理区域。对于停电、断网等局部中断的容灾场景,可以将多可用区加入到容灾方案的设计中。由于可用区之间的网络延时较短,可以更容易实现数据部分的容灾方案,包括数据库、缓存和消息等。
- 多地域部署:为了应对更大范围的灾难故障事件,这些事件可能会影响同一地域的多个可用区,可以将容灾范围扩大至多个地域。但由于地域间网络延时更大,容灾方案的复杂度和实现成本较多可用区会更高一些。
# 2.基于Kubernetes的容灾策略
基于Kubernetes的容灾策略是确保系统在面对各种灾难和故障时能够保持高可用性和数据完整性的关键,因此,主要有以下几种容灾策略:
1、单地域多可用区容灾策略
2、多地域容灾策略
3、混合云容灾策略
不论是哪种容灾策略,都存在冷备、主备、双活等容灾方式,基于成本考虑,这里主要以主备容灾方式进行介绍。
# 2.1、单地域多可用区容灾策略
目前的公有云都提供单地域多可用区选择,该方案的优势在于同一个地域网络打通比较方便且成本相对较低,缺点在于如果该地域出现问题,则整个业务不可用。
[[附件/images/86ca11245a69557f01153a7980f6d1ec_MD5.jpeg|Open: Pasted image 20241111173222.png]]
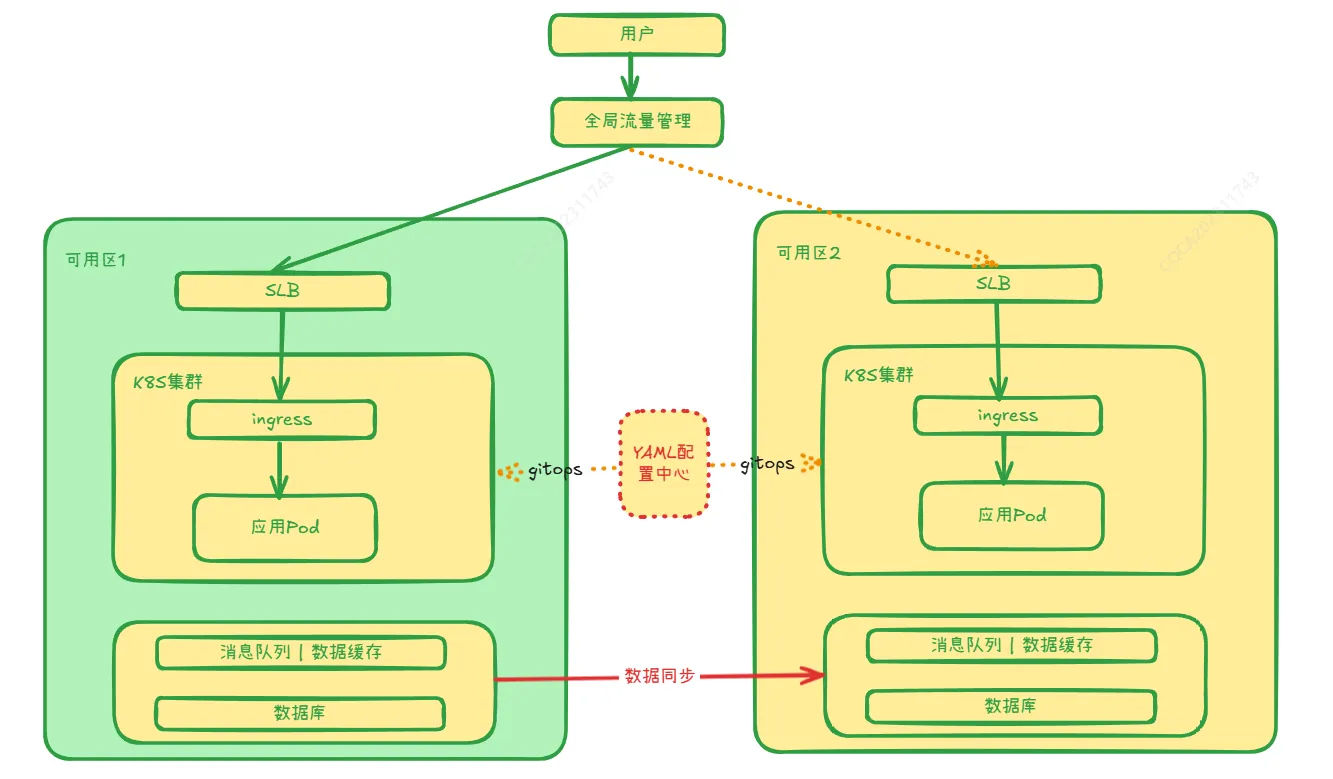
上述方案的设计思路如下:
- 通过
GitOps将应用分发部署到两个Kubernetes集群 - 通过
全局流量管理做DNS解析实现负载分发,并且能够自动触发容灾切换 - 应用部署到
Kubernetes集群,通过Ingress实现流量分发 - 两个集群的应用数量、应用版本、应用配置保持同步,备用节点可以用较少的节点以及较少的副本以节约成本
- 在公有云上购买的消息队列、数据库以及缓存一般都有跨可用区的容灾能力,一般无需专门部署两套环境。
# 2.2、多地域容灾策略
多地域容灾策略和单地域多可用区容灾策略在架构上大致一样,如下:
[[附件/images/c19898995ac9b0a1de762fa5d162bae1_MD5.jpeg|Open: Pasted image 20241111173233.png]]
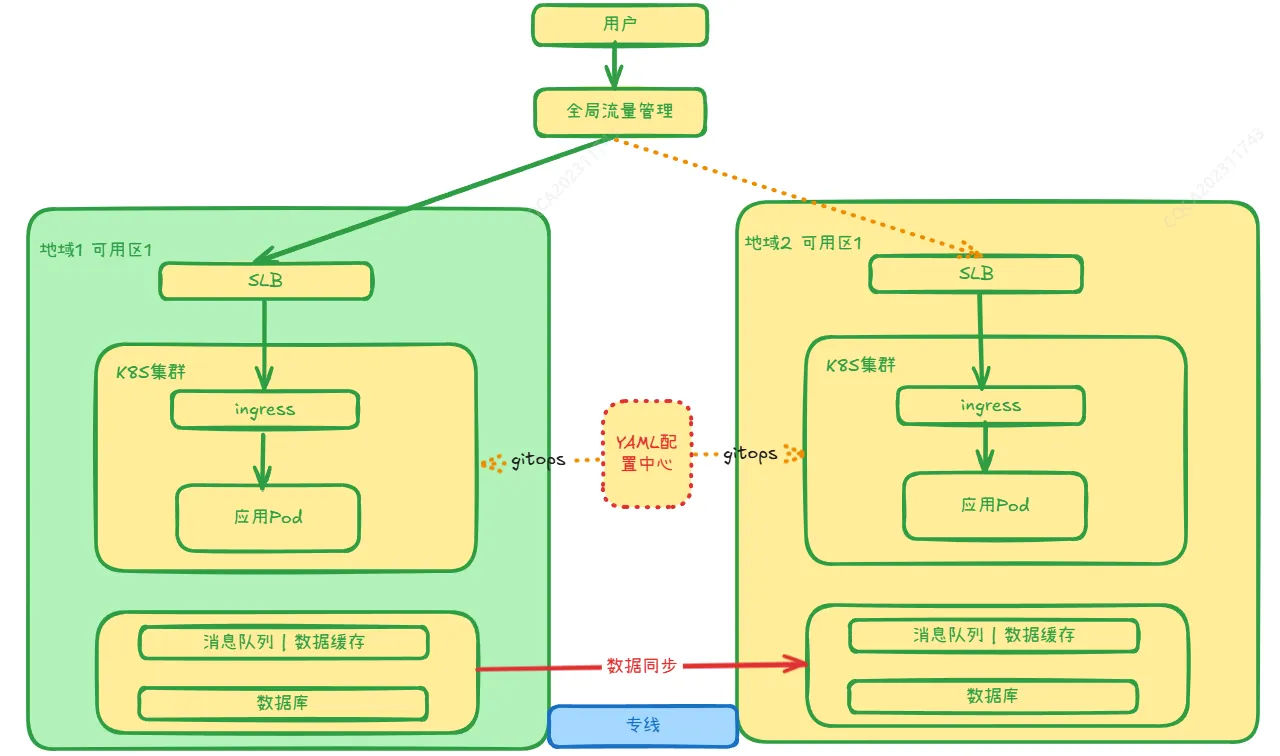
整体设计思路与单地域多可用区容灾策略差不多,不同点在于跨地域对于网络打通要么选择使用云平台的网络工具,比如阿里云的云企业网,要么使用专线打通。另外,数据同步需要使用专业的工具进行同步,比如阿里云的DTS,可以实现大部分的数据同步。
# 2.3、混合云容灾策略
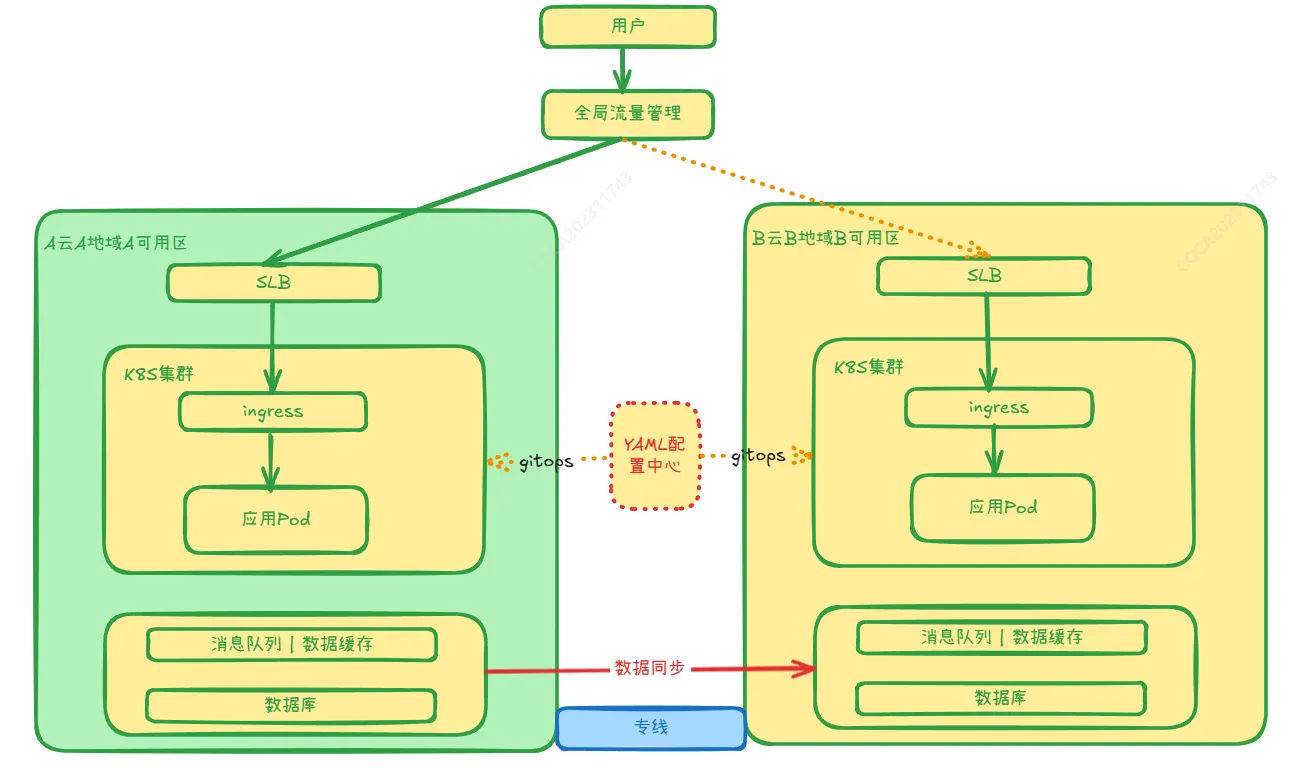
该方案和多地域容灾策略类似,如下:
[[附件/images/6c5e40a2a2734db8d250bc4596da1ef2_MD5.jpeg|Open: Pasted image 20241111173245.png]]
# 3.总结
不论是哪种容灾策略,想要快速恢复,除了数据要保持实时同步,应用配置也需要保持实时同步,这样才能以最小的代价进行恢复。
另外,除了做运行集群的容灾,同时也需要建设好DevOps和对应的监控系统。
DevOps方便管理应用生命周期,需要实现多集群应用管理监控系统方便提前发现问题,及时响应以及快速处理问题,避免造成更大问题。
