 Python之垃圾回收机制
Python之垃圾回收机制
python 在运行程序时,会在内存中开辟一块空间,用于存放程序运行时产生的临时变量,计算完成后,再将结果永久存储。如果数据量过大,内存空间管理不善就会引起 OOM。
# 内存泄漏
(1)、这里的泄漏,并不是说内存出现了信息安全问题,而是程序本身没有设计好,导致程序未能释放不再使用的内存;
(2)、内存泄漏也不是指内存在物理上消失,而是代码在分配了某段内存后,因为程序设计问题,导致失去了对这段内存的控制,从而造成了内存的浪费;
# 计数引用
在 python 中一切皆对象,我们所看到的一切变量,本质上都是对象的一个指针。一个很简单的判断这个对象是否是垃圾对象,可以通过它的引用计数(指针数)来判断,如果计数为 0,则说明这个对象不可达,自然它就是垃圾对象,需要被回收。
来看一个例子:
import os
import psutil
## 显示当前python程序所占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. /1024
print('{} memory used: {}MB'.format(hint, memory))
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
-------------------------------------
initial memory used: 22.66015625MB
after a created memory used: 410.421875MB
finished memory used: 23.25MB
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
从上面可以看出,在执行 func()的时候,内存暴增,在执行完后,内存就恢复了,这是因为变量 a 是局部变量,只有在函数调用的时候才生成,调用完成后就会注释掉,此时列表 a 所指的对象引用数为 0,python 就会执行垃圾回收,回收完内存就回来了。
我们再修改一下上面的例子,把 a 变量申明为全局变量:
import os
import psutil
## 显示当前python程序所占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. /1024
print('{} memory used: {}MB'.format(hint, memory))
def func():
show_memory_info('initial')
global a
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
----------------------------------------------
initial memory used: 24.109375MB
after a created memory used: 411.36328125MB
finished memory used: 411.359375MB
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
我们看到,如果把 a 申明为 global,在 func()执行完后,内存并没有释放,这是因为函数依然在引用全局变量 a,这时候 python 就不会触发垃圾回收机制,所以就依然占用大量内存。
当然,如果我们把函数里的列表返回,内存依然不会释放:
import os
import psutil
## 显示当前python程序所占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. /1024
print('{} memory used: {}MB'.format(hint, memory))
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
return a
a = func()
show_memory_info('finished')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
上面是最常见的几种情况,下面我们来看看 python 内部引用的计数机制。先看一个列子:
import sys
a = []
## 两次引用,一次来自 a,一次来自 getrefcount
print(sys.getrefcount(a))
def func(a):
## 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount
print(sys.getrefcount(a))
func(a)
## 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在
print(sys.getrefcount(a))
--------------------------------------------
2
4
2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
sys.getrefcount()用于查看变量被引用的次数,getrefcount 本身也会引用一次计数。另外,在函数调用发生之时,会产生额外的两次引用,一次来自函数栈,一次来自函数参数。
# 手动释放内存
在 python 中垃圾回收一般都会自动处理,但是免不了有些地方需要手动回收。手动回收的方法很简单,首先调用 del 来删除一个对象,然后调用 gc.collect(),即可手动启动垃圾回收。
import gc
import os
import psutil
## 显示当前python程序所占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. /1024
print('{} memory used: {}MB'.format(hint, memory))
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
del a
gc.collect()
show_memory_info('finish')
## print(a)
--------------------------------------------------------------
initial memory used: 24.3046875MB
after a created memory used: 411.5859375MB
finish memory used: 24.47265625MB
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 循环引用
从上面看垃圾回收很简单,只要判断对象的引用次数是否为 0,但是引用次数为 0 是启动垃圾回收的充要条件吗?我们假设有两个对象,它们互相引用,并且不再被别的对象引用,看下面这个例子:
import gc
import os
import psutil
## 显示当前python程序所占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. /1024
print('{} memory used: {}MB'.format(hint, memory))
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a)
func()
show_memory_info('finished')
--------------------------------------------------
initial memory used: 24.125MB
after a, b created memory used: 799.26171875MB
finished memory used: 799.265625MB
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
从上面可以看到,a,b 都是局部变量,按理说在 func()函数调用结束之后,a,b 两个变量就应该释放,但是从输出可以看到内存依然占用着,也就是说着两个变量依然没有释放,这是因为 a,b 这两个变量相互引用导致它们的引用计数并不为 0,也就导致不会自动触发垃圾回收机制。这种情况我们可以显示调用 gc.collect(),来启动垃圾回收。
python 使用标记清楚算法(mark-sweep)和分代收集(generation)来启动针对循环引用的垃圾回收机制。
(1)、标记清楚算法:对于一个有向图,从起点出发进行遍历,并标记其经过的所有节点,那么结束后,所有没有标记的节点,我们认为它是不可达的,这类节点就会对它们进行垃圾回收。当然,每次的遍历都会耗费巨大的性能,在 python 的垃圾回收实现中,mark-sweep 使用双向链表维护一个数据结构,并且只考虑容器类对象;
(2)、分代收集:python 将对象分为三代,刚刚创立的对象是第 0 代,经过一次垃圾回收后依然存在的对象,便会从上一代移到下一代,而每一代启动自动回收的阙值,则是可以单独指定的。当垃圾回收器重新增对象减去删除对象达到相应的阙值,就会对这一代对象启动垃圾回收。分代收集的思想是新生对象更容易被回收,而存活更久的对象也有更高的概率继续存活下去。通过这种算法可以节约计算量,提升 python 的性能。
从上我们可以知道,引用计数是垃圾回收机制中最简单的一种实现,并且它并非充要条件,它只能算做是充分非必要条件。
# 调试内存泄漏
objgraph 是一个可视化的引用关系包,在这个包中主要的两个函数是 show_refs()和 show_backrefs()。
例子 1:show_refs()
import objgraph
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_refs([a])
2
3
4
5
6
7
8
9
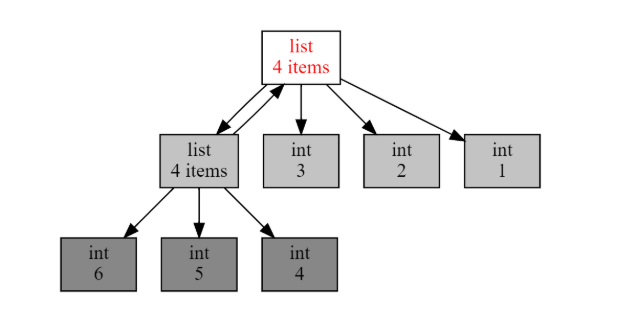
例子 2:show_backrefs()
import objgraph
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_backrefs([a])
2
3
4
5
6
7
8
9
10
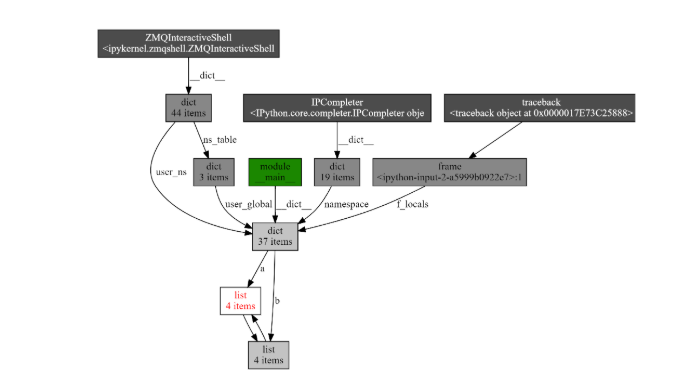
# 总结
(1)、垃圾回收是 python 自带的机制,用于自动释放不会再用到的内存空间
(2)、引用计数是其中最简单的实现,不过它并不是充要条件,因为循环引用需要通过不可达来判断是否回收
(3)、python 的自动回收算法包括标记清除法和分代收集,主要针对循环引用的垃圾回收
(4)、调试内存泄漏,objgraph 是一个很好的可视化工具
作者:
本文链接:https://jokerbai.com
版权声明:本博客所有文章除特别声明外,均采用 署名-非商业性-相同方式共享 4.0 国际 (CC-BY-NC-SA-4.0) 许可协议。转载请注明出处!
- 02
- 使用Zadig从0到1实现持续交付平台07-19
- 03
- 基于Jira的运维发布平台07-19
