 安装 Grafana
安装 Grafana
# 一、安装
Grafana 是一个可视化面板,有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持 Graphite、zabbix、InfluxDB、Prometheus、OpenTSDB、Elasticsearch 等作为数据源,比 Prometheus 自带的图表展示功能强大太多,更加灵活,有丰富的插件,功能更加强大。
镜像地址:https://hub.docker.com/r/grafana/grafana (opens new window)
编辑 deployment 配置清单:
grafana-deploy.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
selector:
matchLabels:
app: grafana
replicas: 1
revisionHistoryLimit: 10
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:6.5.0
imagePullPolicy: IfNotPresent
ports:
- name: grafana
containerPort: 3000
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 100m
memory: 256Mi
volumeMounts:
- name: storage
mountPath: /var/lib/grafana
subPath: grafana
securityContext:
fsGroup: 472
runAsUser: 472
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
这里配置 securityContext 的原因是从 v5.1.0 开始,grafana 的运行用户 ID(userid)和组 ID(groupid)已经改成了 472。而另外两个 env 是用来配置 Grafana 的管理员用户和密码。
配置持久化存储 PVC:
grafana-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
server: xxx.xx.xxx.xx
path: /data/k8s/grafana
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: kube-ops
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
配置 Service 服务:
grafana-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
selector:
app: grafana
type: NodePort
ports:
- name: grafana
port: 3000
2
3
4
5
6
7
8
9
10
11
12
13
14
然后我们会发现 Pod 并没有正常启动:
## kubectl get pod -n kube-ops
NAME READY STATUS RESTARTS AGE
grafana-d8cb7fd98-grqqf 0/1 CrashLoopBackOff 200 16h
2
3
查看其日志如下:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning BackOff 3m39s (x4398 over 16h) kubelet, 172.16.0.52 Back-off restarting failed container
[root@ecs-5704-0003 ~]## kubectl logs grafana-d8cb7fd98-grqqf -n kube-ops
GF_PATHS_DATA='/var/lib/grafana' is not writable.
You may have issues with file permissions, more information here: http://docs.grafana.org/installation/docker/#migration-from-a-previous-version-of-the-docker-container-to-5-1-or-later
mkdir: can't create directory '/var/lib/grafana/plugins': Permission denied
2
3
4
5
6
7
8
我们发现其报权限不足,虽然我们上面定义了其 sercurityContext 为 472,但是 container 在挂载 PVC 的时候目录的 userID 和 groupID 并不是 472,我们可以通过一个 Job 任务来更改其宿主:
grafana-chown-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: grafana-chown
namespace: kube-ops
spec:
template:
metadata:
name: grafana-chown
spec:
containers:
- name: grafana-chown
image: busybox
imagePullPolicy: IfNotPresent
command: ["chown", "-R", "472:472", "/var/lib/grafana"]
volumeMounts:
- name: storage
subPath: grafana
mountPath: /var/lib/grafana
restartPolicy: Never
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
注意:这里定义的 PVC 的名字和上面 Grafana 的 Deployment 中定义的必须一致。
然后我们生成 Job 的配置清单:
## kubectl apply -f grafana-chown-job.yaml
## kubectl get pod -n kube-ops
NAME READY STATUS RESTARTS AGE
grafana-chown-jfp77 0/1 Completed 0 4m22s
grafana-d8cb7fd98-vm8hq 1/1 Running 5 5m41s
2
3
4
5
然后我们发现可以成功运行了。
# 二、配置
# 2.1、添加数据源
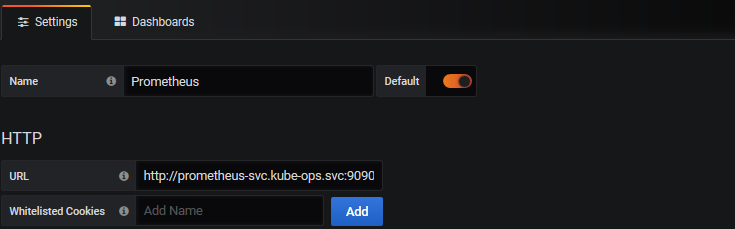
我们这个地方配置的数据源是 Prometheus,所以选择这个 Type 即可,给改数据源添加一个 name:prometheus-ds,最主要的是下面HTTP区域是配置数据源的访问模式。
访问模式是用来控制如何处理对数据源的请求的:
- 服务器(Server)访问模式(默认):所有请求都将从浏览器发送到 Grafana 后端的服务器,后者又将请求转发到数据源,通过这种方式可以避免一些跨域问题,其实就是在 Grafana 后端做了一次转发,需要从 Grafana 后端服务器访问该 URL。
- 浏览器(Browser)访问模式:所有请求都将从浏览器直接发送到数据源,但是有可能会有一些跨域的限制,使用此访问模式,需要从浏览器直接访问该 URL。
由于我们这个地方 Prometheus 通过 NodePort 的方式的对外暴露的服务,所以我们这个地方是不是可以使用浏览器访问模式直接访问 Prometheus 的外网地址,但是这种方式显然不是最好的,相当于走的是外网,而我们这里 Prometheus 和 Grafana 都处于 kube-ops 这同一个 namespace 下面,是不是在集群内部直接通过 DNS 的形式就可以访问了,而且还都是走的内网流量,所以我们这里用服务器访问模式显然更好,数据源地址:http://prometheus-svc.kube-ops.svc:9090,然后其他的配置信息就根据实际情况了,比如 Auth 认证,我们这里没有,所以跳过即可,点击最下方的 Save & Test 提示成功证明我们的数据源配置正确:
# 2.2、添加 Dashboard
Dashboard 官方有很多模板,地址为:https://grafana.com/grafana/dashboards (opens new window)
然后可以搜索找自己想要的模板:
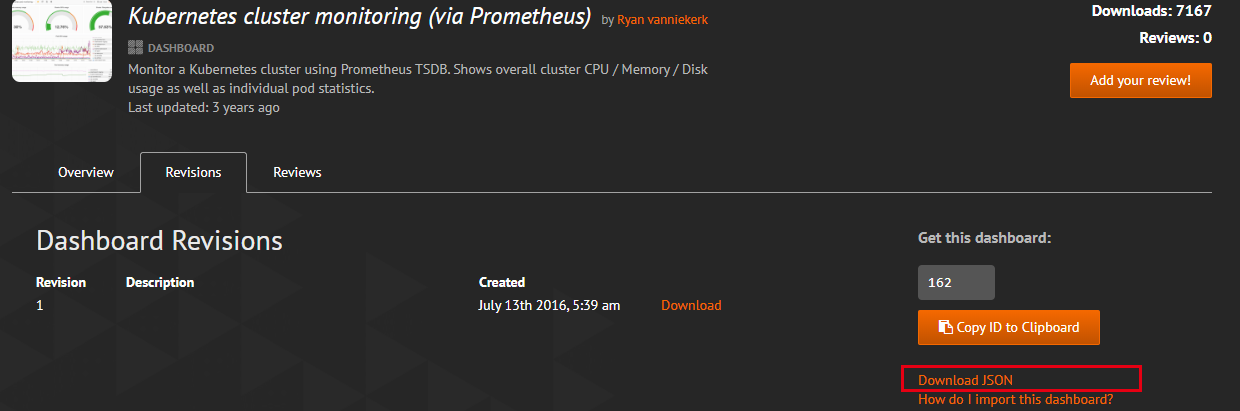
我们这里下载一个:https://grafana.com/grafana/dashboards/162/revisions (opens new window)
然后我们导入即可:
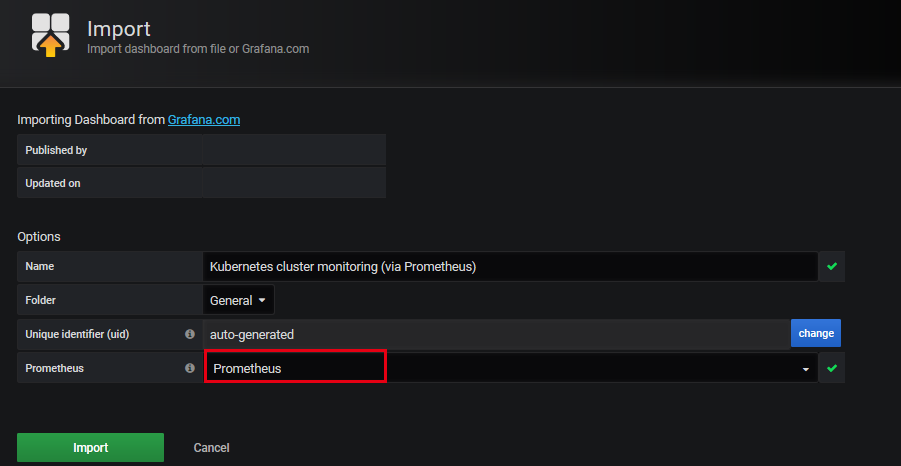
选择我们的数据源。
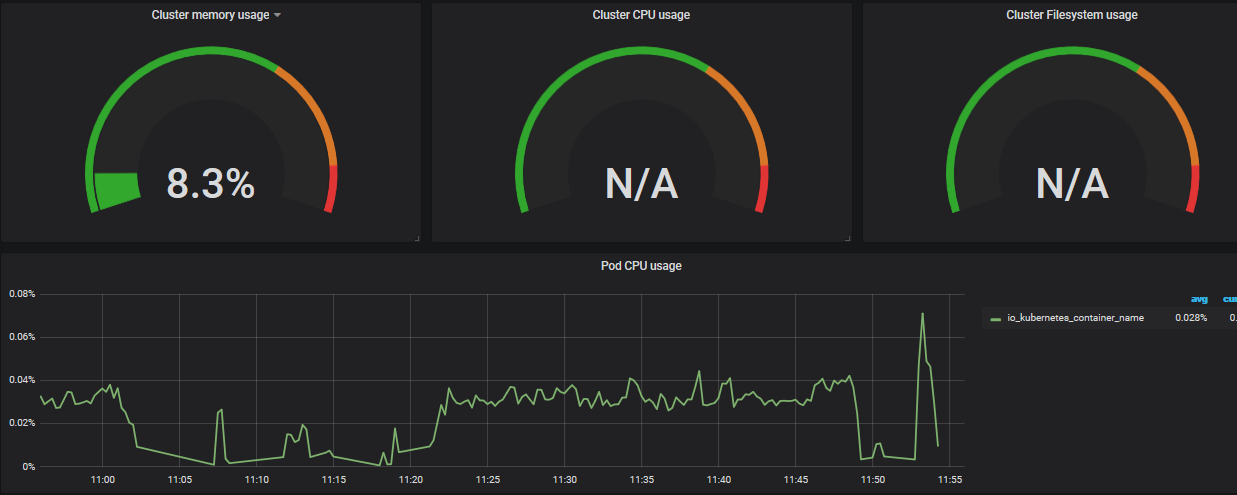
没有出数据的地方可能是 promQL 语句不对,或者是我们在我们采集的指标中没有模板中定义的,我们可以通过 edit 获得现有的 promQL,然后到 prometheus 的 grafa 中调式语句。
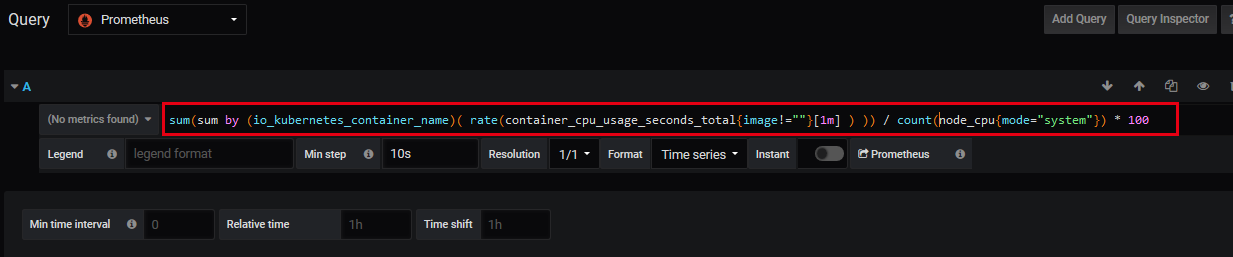
CPU 使用率的 promQL:
sum(sum by (pod_name)( rate(container_cpu_usage_seconds_total{image!=""}[1m] ) )) / count(node_cpu_seconds_total{mode="system"}) * 100
文件系统使用率的 promQL:
(sum(node_filesystem_size_bytes{device="rootfs"}) - sum(node_filesystem_free_bytes{device="rootfs"}) ) / sum(node_filesystem_size_bytes{device="rootfs"}) * 100
Pod Network IO 的 promQL:
sort_desc(sum by (pod_name) (rate (container_network_receive_bytes_total{name!="", pod_name!=""}[1m]) ))
sort_desc(sum by (pod_name) (rate (container_network_transmit_bytes_total{name!="", pod_name!=""}[1m]) ))
2
# 2.3、报警
Grafana 支持很多种形式的报警功能,比如 email、钉钉、slack、webhook 等等.
# 2.3.1、email 报警
要启用 email 报警需要在启动配置文件中/etc/grafana/grafan.ini 开启 SMTP 服务,我们这里同样利用一个 ConfigMap 资源对象挂载到 grafana Pod 中:
grafana-cm.yaml
metadata:
name: grafana-config
namespace: kube-ops
data:
grafana.ini: |
[server]
root_url = http://<你grafana的url地址>
[smtp]
enabled = true
host = smtp.163.com:25
user = ych_1024@163.com
password = <邮箱密码>
skip_verify = true
from_address = ych_1024@163.com
[alerting]
enabled = true
execute_alerts = true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
上面配置了我的 163 邮箱,开启报警功能,当然我们还得将这个 ConfigMap 文件挂载到 Pod 中去:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
selector:
matchLabels:
app: grafana
replicas: 1
revisionHistoryLimit: 10
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:6.5.0
imagePullPolicy: IfNotPresent
ports:
- name: grafana
containerPort: 3000
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 100m
memory: 256Mi
volumeMounts:
- name: storage
mountPath: /var/lib/grafana
subPath: grafana
- name: config
mountPath: /etc/grafana
securityContext:
fsGroup: 472
runAsUser: 472
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana
- name: config
configMap:
name: grafana-config
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
然后我们创建 configmap 并更新 pod。
## kubectl apply -f grafana-cm.yaml
configmap/grafana-config created
## kubectl apply -f grafana-deploy.yaml
deployment.extensions/grafana configured
2
3
4
# 2.3.2、钉钉报警
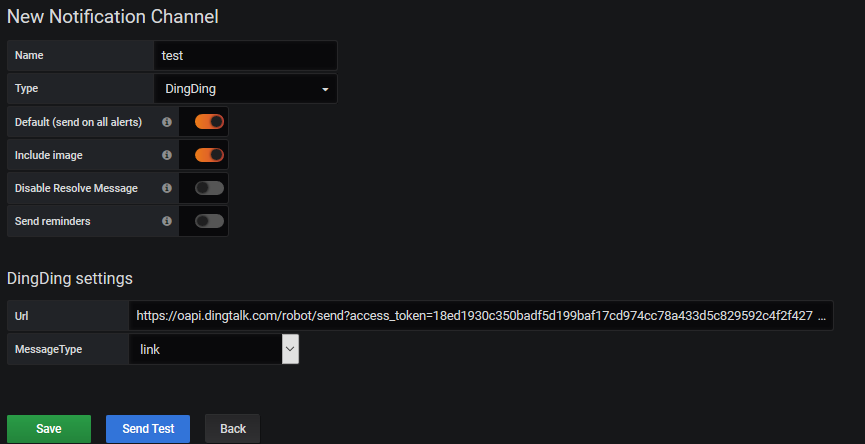
(1)、生成钉钉机器人的 webhook
(2)、测试
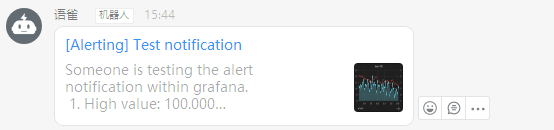
(3)、查看结果
# 2.3.3、添加报警
目前只有 Graph 支持报警功能,所以我们选择 Graph 相关图表,点击编辑,进入 Graph 编辑页面可以看到有一个 Alert 模块,切换过来创建报警:
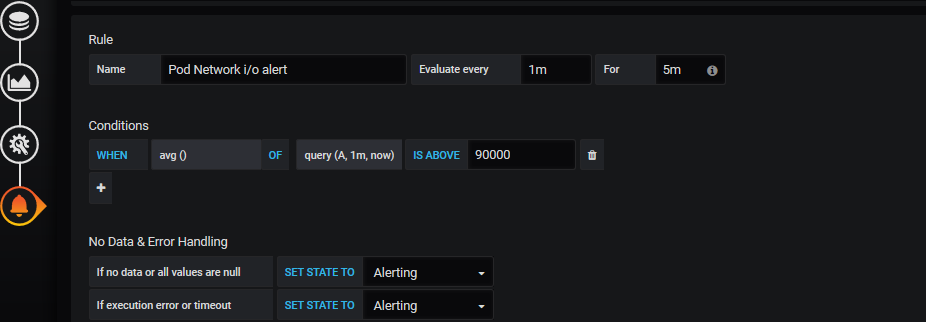
参数说明:
- 1、Alert 名称,可以自定义。
- 2、执行的频率,这里我选择每 60s 检测一次。
- 3、判断标准,默认是 avg,这里是下拉框,自己按需求选择。
- 4、query(A,5m,now),字母 A 代表选择的 metrics 中设置的 sql,也可以选择其它在 metrics 中设置的,但这里是单选。1m 代表从现在起往之前的五分钟,即 1m 之前的那个点为时间的起始点,
now为时间的结束点,此外这里可以自己手动输入时间。 - 5、设置的预警临界点,这里手动输入,和 6 是同样功能,6 可以手动移动,两种操作是等同的。
然后配置报警发送的信息:
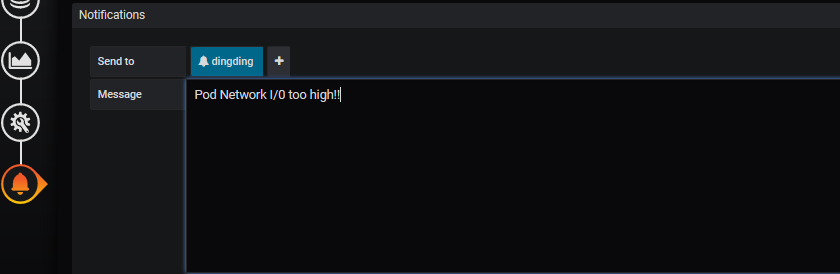
然后达到报警阈值就可以接收到报警了。
